Chapter 20
Simulation Environments
"The proper study of mankind is the science of design." — Herbert A. Simon
Chapter 20 delves into the pivotal role of simulation environments in reinforcement learning (RL), providing a comprehensive exploration of their mathematical foundations, conceptual frameworks, and practical implementations. Beginning with an introduction to the essential components of RL environments, the chapter systematically builds up from the theoretical underpinnings of Markov Decision Processes (MDPs) to the intricacies of state and action spaces. It then navigates through prominent simulation frameworks such as OpenAI’s Gym and Farama’s Gymnasium, highlighting their core abstractions and APIs. Recognizing the current instability of Rust-based crates for these frameworks, the chapter innovatively bridges Python and Rust through various integration strategies, including Foreign Function Interface (FFI) techniques and inter-process communication (IPC). Practical sections offer hands-on guidance for creating custom environments in both Python and Rust, demonstrating how to leverage Rust’s performance and safety features alongside Python’s extensive ecosystem. A detailed case study exemplifies the construction of a hybrid environment, showcasing the seamless interplay between the two languages. Advanced topics address scalability, distributed environments, and future developments, ensuring that readers are well-equipped to push the boundaries of RL simulations. Throughout, the chapter emphasizes best practices, providing clear code examples, visual aids, and actionable insights to facilitate the reader’s journey from foundational concepts to sophisticated implementations.
20.1. Introduction to Simulation Environments
In the realm of Reinforcement Learning (RL), simulation environments serve as the foundational platforms where agents learn to make decisions and execute actions to achieve specific goals. A simulation environment replicates the dynamics of real-world scenarios in a controlled and risk-free setting, allowing RL agents to interact, learn, and optimize their behaviors without the potential consequences associated with real-world experimentation. This abstraction is crucial not only for the initial training phases but also for the evaluation and benchmarking of RL algorithms, ensuring that agents can generalize their learned policies across diverse and complex tasks.
Figure 1: Scopes and applications of simulation in Reinforcement Learning.
The necessity of simulation environments in RL cannot be overstated. In real-world applications such as robotics, autonomous driving, and financial trading, deploying untested agents can lead to significant risks, including physical damage, financial loss, or unintended behaviors. Simulations provide a sandbox where agents can explore a wide range of scenarios, learn from their interactions, and refine their strategies iteratively. Moreover, simulations enable extensive data collection and experimentation, which are often impractical or impossible to achieve in real-world settings due to constraints like time, cost, and safety concerns. By offering a versatile and scalable testing ground, simulation environments accelerate the development and deployment of robust RL solutions.
At the heart of any RL system lies the interaction loop between the agent and the environment. This loop is a continuous cycle where the agent perceives the current state of the environment, selects an action based on its policy, and receives feedback in the form of rewards and new states. Mathematically, this interaction can be modeled using Markov Decision Processes (MDPs), which provide a formal framework for decision-making in stochastic environments. An MDP is defined by a set of states $S$, a set of actions $A$, transition probabilities $P(s'|s,a)$, reward functions $R(s,a)$, and a discount factor $\gamma$. The Markov property ensures that the future state depends only on the current state and action, not on the sequence of events that preceded it, thereby simplifying the complexity of the learning process.
In an RL environment, the state $s$ represents the current situation of the agent within the environment, encapsulating all relevant information needed to make a decision. Actions $a$ are the possible moves or operations the agent can perform, influencing the transition to subsequent states. Rewards $r$ are scalar feedback signals that guide the agent towards desirable behaviors by quantifying the immediate benefit or cost of actions. Transitions $P(s'|s,a)$ describe the probability of moving to a new state $s'$ given the current state $s$ and action $a$, encapsulating the stochastic nature of real-world environments. Together, these components form the backbone of the RL framework, enabling agents to learn optimal policies $\pi(a|s)$ that maximize cumulative rewards over time.
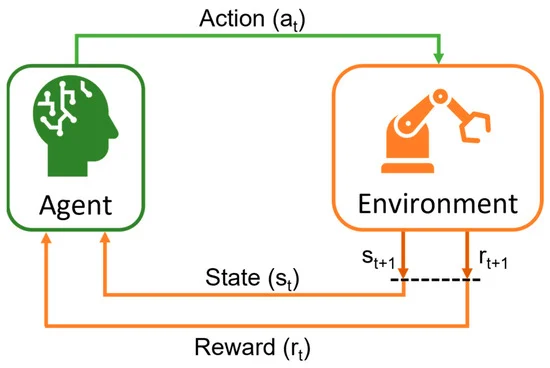
Figure 2: Key ideas of Reinforcement Learning. Simulation is required for the environment.
Simulation environments are pivotal in a multitude of real-world applications where RL can be transformative. In robotics, simulations allow for the training of complex motor control systems that can later be deployed on physical robots, minimizing the risk of hardware damage and reducing development time. Autonomous vehicles benefit from simulations by exposing driving agents to a vast array of traffic scenarios, weather conditions, and unexpected obstacles, fostering the development of safe and reliable navigation policies. In the financial sector, RL agents can be trained in simulated trading environments to devise strategies that optimize portfolio management and trading decisions without the financial risks associated with live trading. Additionally, gaming and entertainment industries utilize simulation environments to create intelligent non-player characters (NPCs) that enhance user experiences by adapting to player behaviors in real-time.
Throughout this introductory section, you will embark on a comprehensive journey through the landscape of simulation environments in reinforcement learning. We will begin by delving into the mathematical foundations of RL environments, elucidating the principles of Markov Decision Processes and the intricacies of state and action spaces. The chapter will then explore prominent simulation frameworks such as OpenAI Gym and Farama Gymnasium, dissecting their architectural designs and conceptual abstractions. Recognizing the current limitations of Rust-based crates for these frameworks, we will investigate innovative integration strategies that bridge Python and Rust, leveraging the strengths of both languages to create robust and efficient RL environments. Practical implementation sections will provide hands-on guidance, featuring Rust code examples that utilize relevant crates to build and optimize custom simulation environments. By the end of this chapter, readers will possess a deep understanding of the theoretical underpinnings, conceptual frameworks, and practical skills necessary to design, implement, and evaluate sophisticated simulation environments for reinforcement learning.
To rigorously define simulation environments in RL, we turn to the mathematical framework of Markov Decision Processes (MDPs). An MDP provides a structured approach to modeling decision-making scenarios where outcomes are partly random and partly under the control of an agent. Formally, an MDP is represented as a tuple $(S, A, P, R, \gamma)$, where:
$S$ is a finite or infinite set of states representing all possible configurations of the environment.
$A$ is a finite or infinite set of actions available to the agent.
$P: S \times A \times S \rightarrow [0,1]$ denotes the state transition probabilities, where $P(s'|s,a)$ is the probability of transitioning to state $s'$ when action $a$ is taken in state $s$.
$R: S \times A \rightarrow \mathbb{R}$ is the reward function, assigning a real-valued reward to each state-action pair.
$\gamma \in [0,1)$ is the discount factor that quantifies the importance of future rewards.
The goal of the agent is to learn a policy $\pi: S \times A \rightarrow [0,1]$ that maximizes the expected cumulative discounted reward over time. The Bellman equation plays a pivotal role in this optimization, providing a recursive relationship for the value function $V^\pi(s)$, which represents the expected return starting from state $s$ and following policy $\pi$:
$$ V^\pi(s) = \sum_{a \in A} \pi(a|s) \left[ R(s,a) + \gamma \sum_{s' \in S} P(s'|s,a) V^\pi(s') \right] $$
This equation encapsulates the trade-off between immediate rewards and future value, guiding the agent towards optimal decision-making. Understanding and effectively utilizing these mathematical foundations is essential for designing robust simulation environments that accurately reflect the complexities of real-world scenarios.
Building upon the foundational framework of Markov Decision Processes (MDPs), it is essential to recognize that many real-world scenarios present complexities that extend beyond the assumptions inherent in MDPs. Specifically, in numerous applications, an agent does not have full visibility of the environment's state. This limitation gives rise to the more sophisticated framework of Partially Observable Markov Decision Processes (POMDPs), which provide a more realistic and nuanced model for decision-making under uncertainty.
A Partially Observable Markov Decision Process (POMDP) extends the MDP framework by incorporating the notion that the agent receives only partial information about the true state of the environment. Formally, a POMDP is defined as a tuple $(S, A, P, R, \Omega, O, \gamma)$, where:
$S$, $A$, $P$, $R$, and $\gamma$ retain their definitions from the MDP framework, representing the set of states, actions, state transition probabilities, reward function, and discount factor, respectively.
$\Omega$ is a finite or infinite set of observations that the agent can receive.
$O: S \times A \times \Omega \rightarrow [0,1]$ denotes the observation probabilities, where $O(o|s',a)$ is the probability of observing $o$ given that the agent took action aaa and transitioned to state $s'$.
In a POMDP, the agent does not directly observe the underlying state $s \in S$. Instead, after taking an action $a$, the agent receives an observation $o \in \Omega$ that provides partial information about the new state $s'$. This partial observability introduces significant challenges in both the representation and computation of optimal policies, as the agent must infer the hidden state based on the history of actions and observations.
The introduction of observations transforms the agent's knowledge from being state-based to belief-based. A belief state $b$ is a probability distribution over all possible states, representing the agent's current estimate of the environment's state given its history of actions and observations. The belief update process involves Bayesian inference, where the agent updates its belief state based on the new observation received after taking an action. Mathematically, the belief update can be expressed as:
$$ b'(s') = \frac{O(o|s',a) \sum_{s \in S} P(s'|s,a) b(s)}{P(o|a,b)} $$
where $P(o|a,b)$ is the probability of receiving observation $o$ given action $a$ and belief state $b$.
Solving POMDPs is inherently more complex than solving MDPs due to the additional layer of uncertainty introduced by partial observability. The optimal policy in a POMDP must map belief states to actions, rather than mapping concrete states to actions as in MDPs. This shift necessitates more advanced algorithms and representations, such as belief state approximation, policy search methods, and the use of recurrent neural networks to maintain an internal state that captures historical information.
In the context of simulation environments, incorporating POMDPs allows for the creation of more realistic and challenging scenarios where the agent must operate under uncertainty and make inferences based on incomplete information. For instance, in autonomous driving simulations, an agent may not have perfect visibility of all surrounding vehicles and obstacles due to sensor limitations or environmental conditions like fog and rain. Similarly, in robotics, an agent may only have access to noisy sensor data, requiring it to infer the true state of its environment to perform tasks effectively.
By modeling environments as POMDPs, researchers and practitioners can develop and evaluate RL algorithms that are better suited for real-world applications where uncertainty and partial observability are the norms rather than the exceptions. This advancement not only enhances the robustness and adaptability of RL agents but also bridges the gap between theoretical research and practical deployment in complex, dynamic environments.
To bridge theory with practice, let us explore the implementation of a simple RL environment in Rust. We'll utilize the gym-rs crate, a Rust binding for OpenAI Gym, to create a custom environment. This example will demonstrate defining state and action spaces, implementing environment dynamics, and integrating with an RL agent.
Now, let's implement a basic grid world environment. The provided code simulates a basic reinforcement learning environment called "GridWorld," where an agent navigates a 5x5 grid to reach a predefined goal. The environment is structured as a grid with a start point at the top-left corner (0,0) and a goal at the bottom-right corner (4,4). The agent can take one of four actions—move up, down, left, or right—until it either reaches the goal or exhausts its moves.
[dependencies]
gym-rs = "0.3.0"
rand = "0.8.5"
use gym_rs::{Action, Env, Observation, Reward};
use rand::Rng;
/// Represents the state of the agent in the grid.
#[derive(Debug, Clone, PartialEq)]
struct GridState {
x: usize,
y: usize,
}
/// Defines the possible actions the agent can take.
#[derive(Clone)]
enum GridAction {
Up,
Down,
Left,
Right,
}
/// Custom GridWorld environment implementing the Env trait.
struct GridWorld {
state: GridState,
goal: GridState,
grid_size: usize,
}
impl GridWorld {
/// Initializes a new GridWorld environment.
fn new(grid_size: usize) -> Self {
GridWorld {
state: GridState { x: 0, y: 0 },
goal: GridState {
x: grid_size - 1,
y: grid_size - 1,
},
grid_size,
}
}
/// Resets the environment to the initial state.
fn reset(&mut self) -> GridState {
self.state = GridState { x: 0, y: 0 };
self.state.clone()
}
/// Applies an action and returns the new state, reward, and done flag.
fn step(&mut self, action: &GridAction) -> (GridState, Reward, bool) {
match action {
GridAction::Up if self.state.y > 0 => self.state.y -= 1,
GridAction::Down if self.state.y < self.grid_size - 1 => self.state.y += 1,
GridAction::Left if self.state.x > 0 => self.state.x -= 1,
GridAction::Right if self.state.x < self.grid_size - 1 => self.state.x += 1,
_ => (), // Invalid move, no state change
}
// Reward structure: -1 for each step, +10 for reaching the goal
let reward = if self.state == self.goal {
10.0
} else {
-1.0
};
// Episode is done if the agent reaches the goal
let done = self.state == self.goal;
(self.state.clone(), reward, done)
}
}
impl Env for GridWorld {
type State = GridState;
type Action = GridAction;
fn reset(&mut self) -> Observation<Self::State> {
Observation::new(self.reset())
}
fn step(&mut self, action: Action<Self::Action>) -> (Observation<Self::State>, Reward, bool) {
let (new_state, reward, done) = self.step(&action.unwrap());
(Observation::new(new_state), reward, done)
}
}
fn main() {
let mut env = GridWorld::new(5);
let mut rng = rand::thread_rng();
// Reset the environment
let mut observation = env.reset();
println!("Initial State: {:?}", observation.state);
// Simple random agent
loop {
// Choose a random action
let action = Action::new(match rng.gen_range(0..4) {
0 => GridAction::Up,
1 => GridAction::Down,
2 => GridAction::Left,
_ => GridAction::Right,
});
// Take a step in the environment
let (new_observation, reward, done) = env.step(action);
println!(
"Action: {:?}, New State: {:?}, Reward: {}, Done: {}",
action.unwrap(), new_observation.state, reward, done
);
observation = new_observation;
if done {
println!("Goal reached!");
break;
}
}
}
The provided Rust code constructs a reinforcement learning environment using the gym_rs crate, which offers standardized interfaces for agent-environment interactions. At its core, the GridWorld environment represents the agent's state within a 5x5 grid using the GridState struct, defined by x and y coordinates. The GridAction enum specifies the agent's possible actions—moving up, down, left, or right—while the GridWorld struct implements the Env trait, encapsulating the current state, goal state, and grid size to define the environment's structure and dynamics. The reset method initializes the agent's position at (0, 0), setting up the environment for a new episode. The step method processes the agent's selected action, updates its state, calculates rewards (-1 per step, +10 for reaching the goal), and determines if the goal is achieved. Additionally, the rand crate is used to simulate a random agent, choosing actions arbitrarily. The main function demonstrates this interaction loop, highlighting the fundamentals of reinforcement learning and Rust's capability to create efficient, robust simulation environments.
This example illustrates the fundamental components of an RL environment: state representation, action definitions, environment dynamics, and reward structures. By implementing the Env trait, we ensure compatibility with RL algorithms that can interact seamlessly with the environment. Leveraging Rust’s performance and safety features, this custom environment provides a robust foundation for training and evaluating RL agents. When running the code, the agent begins at (0, 0) and performs random moves until it reaches the goal at (4, 4). The output logs each action, the resulting state, the immediate reward, and whether the goal has been achieved. The program demonstrates key reinforcement learning principles, including state transitions and a simple reward system. The random agent is inefficient, often taking many steps to reach the goal. This highlights the importance of more advanced strategies, such as policy optimization, for achieving better performance in similar tasks.
Simulation environments extend their utility across a myriad of real-world applications, each benefiting uniquely from the controlled and adaptable nature of simulations. In robotics, for instance, simulation environments enable the training of complex motor control systems without the wear and tear associated with physical hardware. Robots can practice navigation, manipulation, and interaction tasks in diverse simulated terrains, accelerating the development cycle and ensuring safety before deployment in real-world settings.
Autonomous vehicles represent another critical domain where simulation environments are indispensable. These environments allow for the testing of driving policies under a vast array of conditions, including different weather scenarios, traffic densities, and unexpected obstacles. By simulating rare and hazardous situations, developers can train autonomous systems to handle edge cases that would be impractical or dangerous to replicate in real life. This comprehensive training enhances the reliability and safety of autonomous driving technologies.
In the financial sector, RL agents trained within simulation environments can devise sophisticated trading strategies and portfolio management techniques. Simulated trading environments can mimic market conditions, economic indicators, and investor behaviors, providing a rich dataset for agents to learn from. This approach minimizes the financial risks associated with live trading experiments and allows for extensive backtesting of strategies across various market scenarios.
Gaming and entertainment industries also leverage simulation environments to create intelligent non-player characters (NPCs) that adapt to player behaviors in real-time. By training RL agents within simulated game environments, developers can enhance the realism and challenge of NPCs, providing more engaging and dynamic gaming experiences. Additionally, multi-agent simulations facilitate the development of cooperative and competitive behaviors, enriching the interactive elements of games.
These examples underscore the versatility and critical importance of simulation environments in advancing RL applications. By providing a versatile platform for experimentation, training, and evaluation, simulation environments empower developers and researchers to push the boundaries of what RL agents can achieve across diverse and complex tasks.
Recognizing the current limitations of Rust-based crates for these frameworks, we will explore innovative integration strategies that bridge Python and Rust, harnessing the strengths of both languages to create robust and efficient RL environments. Practical implementation sections will provide hands-on guidance, featuring Rust code examples that utilize relevant crates to build and optimize custom simulation environments. These sections will demonstrate how to define state and action spaces, implement environment dynamics, and integrate performance-critical components using Rust, all while maintaining compatibility with Python-based RL algorithms.
Below is another Rust code for the custom GridWorld environment, utilizing the gym-rs crate. The main differences compared to previous code lie in their implementation of the gym_rs environment and their complexity. This code is more comprehensive and uses more advanced Rust features, such as implementing additional traits like Sample, Serialize, and Deserialize, and includes more detailed space definitions with Discrete and BoxR observation spaces. It also introduces more robust randomization with Pcg64, provides a metadata method, adds rendering capabilities, and includes more explicit type handling with ActionReward and EnvProperties traits. In contrast, the previous code is a simpler, more straightforward implementation of the same GridWorld environment, with less explicit type definitions and fewer trait implementations, focusing on the core mechanics of the grid-based reinforcement learning scenario.
The code implements a customized RL environment called GridWorld, where an agent navigates a grid from a starting point $(0,0)$ to a goal point at the bottom-right corner. The environment is structured using the gym_rs crate, following the standard gym-like interface with methods for resetting the environment and taking steps. The agent uses a random action selection strategy, choosing between moving up, down, left, or right in each iteration. The environment provides a reward system where the agent receives -1 for each move and +10 for reaching the goal, with the episode terminating once the goal is achieved. The code demonstrates a basic reinforcement learning setup, showing how to create a custom environment, implement the Env trait, and simulate an agent's interactions with the environment through random exploration.
[dependencies]
gym-rs = "0.3.0"
rand = "0.8.5"
rand_pcg = "0.3.1"
serde = "1.0.216"
serde_json = "1.0.133"
use gym_rs::{
core::{ActionReward, Env, EnvProperties},
spaces::{BoxR, Discrete},
utils::custom::structs::Metadata,
utils::custom::traits::Sample, // Import Sample from the correct location
utils::renderer::{RenderMode, Renders},
};
use rand::Rng;
use rand_pcg::Pcg64; // Use a publicly accessible RNG from rand_pcg
use serde::{Deserialize, Serialize};
#[derive(Debug, Clone, PartialEq, Serialize, Deserialize)]
struct GridState {
x: usize,
y: usize,
}
// Implement required traits for the observation type
impl Sample for GridState {}
impl Into<Vec<f64>> for GridState {
fn into(self) -> Vec<f64> {
vec![self.x as f64, self.y as f64]
}
}
#[derive(Debug, Clone, Serialize, Deserialize)]
enum GridAction {
Up,
Down,
Left,
Right,
}
#[derive(Debug, Clone, Serialize, Deserialize)]
struct GridWorld {
state: GridState,
goal: GridState,
grid_size: usize,
#[serde(skip)]
action_space: Discrete,
#[serde(skip)]
observation_space: BoxR<f64>,
#[serde(skip)]
metadata: Metadata<Self>,
#[serde(skip)]
random: Pcg64, // Use Pcg64 instead of Lcg128Xsl64
}
impl GridWorld {
fn new(grid_size: usize) -> Self {
let action_space = Discrete { n: 4 };
let observation_space = BoxR::<f64>::new(
vec![0.0, 0.0],
vec![(grid_size - 1) as f64, (grid_size - 1) as f64],
);
let metadata = Metadata::default();
let random = Pcg64::seed_from_u64(0);
GridWorld {
state: GridState { x: 0, y: 0 },
goal: GridState {
x: grid_size - 1,
y: grid_size - 1,
},
grid_size,
action_space,
observation_space,
metadata,
random,
}
}
fn move_agent(&mut self, action: &GridAction) {
match action {
GridAction::Up if self.state.y > 0 => self.state.y -= 1,
GridAction::Down if self.state.y < self.grid_size - 1 => self.state.y += 1,
GridAction::Left if self.state.x > 0 => self.state.x -= 1,
GridAction::Right if self.state.x < self.grid_size - 1 => self.state.x += 1,
_ => (),
}
}
}
impl Env for GridWorld {
type Action = GridAction;
type Observation = GridState;
type ResetInfo = ();
type Info = ();
fn reset(
&mut self,
_seed: Option<u64>,
_flag: bool,
_options: Option<BoxR<Self::Observation>>, // Updated type here
) -> (Self::Observation, Option<Self::ResetInfo>) {
self.state = GridState { x: 0, y: 0 };
(self.state.clone(), None)
}
fn step(
&mut self,
action: Self::Action,
) -> ActionReward<Self::Observation, Self::Info> {
self.move_agent(&action);
let reward = if self.state == self.goal { 10.0 } else { -1.0 };
let done = self.state == self.goal;
(self.state.clone(), reward, done, ())
}
fn render(&mut self, _mode: RenderMode) -> Renders {
println!("Current state: {:?}", self.state);
Renders::None
}
fn close(&mut self) {}
}
impl EnvProperties for GridWorld {
type ActionSpace = Discrete;
type ObservationSpace = BoxR<f64>;
fn metadata(&self) -> &Metadata<Self> {
&self.metadata
}
fn rand_random(&self) -> &Pcg64 {
&self.random
}
fn action_space(&self) -> &Self::ActionSpace {
&self.action_space
}
fn observation_space(&self) -> &Self::ObservationSpace {
&self.observation_space
}
}
fn main() {
let mut env = GridWorld::new(5);
let mut rng = rand::thread_rng();
let (mut observation, _) = env.reset(None, true, None);
println!("Initial State: {:?}", observation);
loop {
let action = match rng.gen_range(0..4) {
0 => GridAction::Up,
1 => GridAction::Down,
2 => GridAction::Left,
_ => GridAction::Right,
};
let (new_observation, reward, done, _) = env.step(action.clone());
println!(
"Action: {:?}, New State: {:?}, Reward: {}, Done: {}",
action, new_observation, reward, done
);
observation = new_observation;
if done {
println!("Goal reached!");
break;
}
}
}
The GridWorld environment in this Rust code is a structured playground for reinforcement learning, simulating an agent's navigation through a grid. At its core, the GridState struct tracks the agent's position using x and y coordinates, while the GridAction enum defines the possible movements: up, down, left, and right. The GridWorld struct manages the environment's state, including the current position, goal location, and grid size. When initialized, it sets up a grid where the agent starts at (0, 0) and aims to reach the bottom-right corner. The reset method returns the agent to the starting point, preparing for a new episode, and the step method processes the agent's actions by updating its position, calculating rewards (positive for reaching the goal, negative for each move), and determining when the episode ends. The main function demonstrates this by creating an agent that randomly explores the grid, moving and receiving feedback until it successfully reaches the goal, showcasing a basic yet fundamental approach to reinforcement learning interaction.
This implementation serves as a foundational example of how to create custom RL environments in Rust, leveraging the safety and performance benefits of the language. By adhering to the Gym interface, this environment can seamlessly integrate with a wide range of RL agents and algorithms, facilitating robust and efficient training processes.
The introduction to simulation environments lays the groundwork for understanding the pivotal role these environments play in the development and evaluation of reinforcement learning agents. By defining simulation environments through the lens of Markov Decision Processes, we establish a rigorous mathematical framework that captures the essence of decision-making under uncertainty. The exploration of the RL interaction loop and its core components—states, actions, rewards, and transitions—provides a clear conceptual model that underpins all RL algorithms.
Through practical implementation in Rust, we bridge the gap between theory and practice, demonstrating how to construct a simple yet effective RL environment that adheres to established frameworks like OpenAI Gym. This hands-on example not only reinforces the theoretical concepts but also highlights the advantages of using Rust for building high-performance and reliable simulation environments. As we progress through the chapter, we will delve deeper into more complex environments, integration strategies between Python and Rust, and advanced techniques for optimizing and scaling RL simulations.
Ultimately, mastering simulation environments is essential for anyone seeking to advance in the field of reinforcement learning. These environments provide the necessary infrastructure for training agents, testing hypotheses, and benchmarking algorithm performance, all while ensuring that the learning processes are both safe and scalable. By equipping readers with both the theoretical knowledge and practical skills to design and implement sophisticated simulation environments, this chapter serves as a cornerstone for developing robust and effective RL systems that can tackle real-world challenges with confidence and precision.
20.2. Prominent Simulation Frameworks
The history and evolution of reinforcement learning simulation frameworks have been shaped by the growing need to standardize, benchmark, and accelerate research in complex decision-making environments. In the early days of RL, researchers often had to craft their own environments, leading to a proliferation of ad-hoc implementations that were difficult to compare or reproduce. The arrival of standardized frameworks like OpenAI Gym revolutionized the field by providing a unified interface for interacting with a wide variety of simulated tasks. OpenAI Gym emerged as a response to the community’s call for better benchmarks, offering a consistent environment API and a diverse suite of tasks ranging from classic control problems to high-dimensional Atari games. More recently, the Farama Gymnasium project—an effort led by the RL community—aims to extend, refine, and modernize the Gym interface, addressing legacy issues and incorporating new design principles. By integrating lessons learned from Gym’s widespread adoption and feedback from researchers, Gymnasium builds upon its predecessor’s successes and sets the stage for even more robust and flexible RL simulation frameworks.
Figure 3: Farama projects - the World's Open Source Reinforcement Learning Tools (www.farama.org).
From a conceptual standpoint, frameworks like Gym and Gymnasium are popular because they implement a clear and consistent abstraction that aligns neatly with the Markov Decision Process (MDP) formulation. In an MDP, an agent interacts with an environment defined by a set of states $S$, a set of actions $A$, a transition function $P(s'|s,a)$, and a reward function $R(s,a)$. The agent selects an action $a$ based on the current state $s$ and receives a reward $r$ along with a new state $s'$. Over time, the agent’s goal is to learn a policy $\pi(a|s)$ that maximizes the expected sum of discounted rewards. Frameworks like Gym and Gymnasium encapsulate this cycle with a standardized interface, typically providing reset() and step() functions. The reset() function returns an initial state observation from the environment, while step(action) takes an action and returns the next observation, the received reward, a boolean flag indicating whether the episode has ended, and additional diagnostic information. This tight alignment with the MDP structure greatly simplifies implementation details, allowing researchers to focus on algorithm development rather than environment engineering.
Mathematically, these frameworks make the MDP formulation more tangible. Consider an agent interacting with an environment: at each time step $t$, the environment returns a state $s_t$. The agent picks an action $a_t$, and the environment responds with a new state $s_{t+1}$ drawn from the probability distribution $P(s_{t+1}|s_t,a_t)$ and a reward $r_t = R(s_t,a_t)$. Over an episode, the agent accumulates rewards $\sum_t \gamma^t r_t$, where $\gamma \in [0,1)$ is the discount factor. By providing a consistent API, Gym and Gymnasium handle the complexities of state transitions, reward computations, and environmental bookkeeping, leaving the researcher free to experiment with different policies, function approximators, and training schemes. Though the underlying mathematics might seem abstract, the frameworks distill this complexity into a few intuitive methods and a well-defined data flow.
On a practical level, selecting the right framework for a given research or development need can be guided by a comparison of their features. OpenAI Gym boasts a wide variety of environments and a large user community, making it an excellent starting point for many researchers. Farama Gymnasium, on the other hand, refines the API and introduces improved environment wrappers, clearer versioning, and better extensibility. A rough comparison of their features is presented below:
~~~{list-table} :header-rows: 1 :name: F7pF9vgn4H
* - Feature
OpenAI Gym
Farama Gymnasium
* - Environment Diversity
Extensive (Atari, MuJoCo, Classic Control, etc.)
Comparable, with plans to expand and modernize
* - API Stability
Mature but some legacy issues
Modernized API, improved wrapper design
* - Community & Ecosystem
Large user base, many external tools
Growing community, building upon Gym’s legacy
* - Extensibility & Modularity
Good, but certain patterns are now outdated
Enhanced extensibility and clearer best practices
* - Python Integration
Native Python environments
Python-centric, aiming for multi-language support
* - Versioning & Benchmarking
Basic versioning, no leaderboards
Clear versioning, community-driven curation and standardization
When choosing a framework, one might consider criteria such as the complexity of the tasks at hand, the desired level of extensibility, compatibility with existing libraries, and community support. For those embarking on a new RL project, Gym remains an excellent entry point due to its widespread adoption and extensive documentation. For researchers looking to embrace cutting-edge design principles and more flexible integration with future environment collections, Gymnasium provides a promising alternative. Ultimately, the decision depends on balancing current research needs, computational resources, and the long-term vision for the project.
While Gym and Gymnasium are primarily Python-based ecosystems, the RL community continuously explores polyglot and high-performance approaches. The gym_rs is a Rust implementation of environments inspired by OpenAI's Gym, which is widely used for developing and comparing reinforcement learning (RL) algorithms. This library provides simulation environments for various control tasks, enabling developers to interact programmatically with these environments while focusing on creating, training, and evaluating RL agents. It supports classical control problems like MountainCar, CartPole, and others, providing tools for rendering, state observation, and reward-based decision-making in a modular and efficient way.
use gym_rs::{
core::{ActionReward, Env},
envs::classical_control::mountain_car::MountainCarEnv,
utils::renderer::RenderMode,
};
use rand::{thread_rng, Rng};
fn main() {
let mut mc = MountainCarEnv::new(RenderMode::Human);
let _state = mc.reset(None, false, None);
let mut rng = thread_rng();
let mut end: bool = false;
let mut episode_length = 0;
while !end {
if episode_length > 200 {
break;
}
let action = rng.gen_range(0..3);
let ActionReward { done, .. } = mc.step(action);
episode_length += 1;
end = done;
println!("episode_length: {}", episode_length);
}
mc.close();
for _ in 0..200 {
let action = rng.gen_range(0..3);
mc.step(action);
episode_length += 1;
println!("episode_length: {}", episode_length);
}
}
The provided code demonstrates the use of gym_rs to interact with the MountainCar environment, a classic RL problem where an agent must learn to push a car up a mountain using limited momentum and gravity. The environment is initialized in human rendering mode, and the car's state is reset at the beginning. A random policy is used to choose actions (0, 1, or 2, corresponding to left, no action, or right), and the simulation steps forward with each action. The episode ends when the car reaches the goal or exceeds 200 time steps. The episode_length counter keeps track of the number of actions taken, and the program prints this value after each step. The loop ensures the environment closes properly and performs an additional set of actions for demonstration purposes.
The next code demonstrates the use of the gym_rs library to interact with the CartPole environment, a classic reinforcement learning (RL) task. The CartPole task involves balancing a pole on a moving cart by applying left or right forces, where the agent receives rewards for keeping the pole upright and penalized if the pole falls or the cart moves out of bounds. The environment is initialized in human rendering mode, and the simulation runs multiple episodes, using random actions to explore the environment.
use gym_rs::{
core::Env, envs::classical_control::cartpole::CartPoleEnv, utils::renderer::RenderMode,
};
use ordered_float::OrderedFloat;
use rand::{thread_rng, Rng};
fn main() {
let mut env = CartPoleEnv::new(RenderMode::Human);
env.reset(None, false, None);
const N: usize = 15;
let mut rewards = Vec::with_capacity(N);
let mut rng = thread_rng();
for _ in 0..N {
let mut current_reward = OrderedFloat(0.);
for _ in 0..475 {
let action = rng.gen_range(0..=1);
let state_reward = env.step(action);
current_reward += state_reward.reward;
if state_reward.done {
break;
}
}
env.reset(None, false, None);
rewards.push(current_reward);
}
println!("{:?}", rewards);
}
The program initializes the CartPole environment and runs a series of episodes (N = 15). In each episode, the agent takes up to 475 steps, choosing random actions (0 for left or 1 for right) and accumulating rewards based on the environment's feedback. The cumulative reward for each episode is tracked using the OrderedFloat wrapper to ensure proper handling of floating-point comparisons. If the episode ends prematurely due to the pole falling or the cart moving out of bounds, the environment resets to start a new episode. After all episodes are completed, the program prints the collected rewards for each episode, showcasing the agent's random performance in the CartPole environment.
The next code connects to a running Gym server via gym-rs, a Rust crate providing interfaces to Gym environments through a REST API. After creating an instance of a classic control environment like CartPole-v1, the code resets the environment to obtain the initial observation. It then enters a loop, choosing random actions at each step and printing out the resulting observations, rewards, and termination signals. Although this example uses a simplistic random policy, it clearly demonstrates the RL interaction loop in a Rust-based setting. By substituting random actions with learned policies, researchers can integrate advanced RL algorithms implemented in Rust, harnessing both the performance and safety benefits of the language while interacting seamlessly with popular RL frameworks.
use gym_rs::core::Env;
use gym_rs::envs::remote::RemoteEnv;
use rand::{thread_rng, Rng};
fn main() {
// Connect to a running Gym server. Make sure you have a Gym HTTP server running,
// for example using the gym_http_server tool provided by gym-http-api or similar.
// Adjust the URL and environment ID as needed.
let mut env = RemoteEnv::new("CartPole-v1", "http://127.0.0.1:5000", None)
.expect("Failed to connect to the remote Gym server.");
// Reset the environment to get the initial observation.
let mut observation = env.reset(None, false, None);
println!("Initial observation: {:?}", observation);
let mut rng = thread_rng();
// Run a loop of interaction steps. Press Ctrl+C to stop.
loop {
// Select a random action. For CartPole-v1, valid actions are typically 0 or 1.
let action = rng.gen_range(0..2);
// Take a step in the environment using the chosen action.
let step_result = env.step(action);
// Print the result of the step: observation, reward, and whether the episode ended.
println!(
"Action: {}, Observation: {:?}, Reward: {}, Done: {}",
action,
step_result.observation,
step_result.reward,
step_result.done
);
// If the episode ended, reset the environment.
if step_result.done {
observation = env.reset(None, false, None);
println!("Episode finished. Resetting environment. New initial observation: {:?}", observation);
}
}
}
Gymnasium is a robust and actively maintained fork of OpenAI’s seminal Gym library, designed to serve as a comprehensive API for single-agent reinforcement learning (RL) environments. With its simple, pythonic interface, Gymnasium excels in representing a wide array of RL problems, ranging from classical control tasks like CartPole, Pendulum, and MountainCar to more complex environments such as MuJoCo and Atari games. One of its standout features is the compatibility wrapper, which ensures seamless integration with legacy Gym environments, thereby facilitating the transition for projects and researchers accustomed to the original Gym framework. Gymnasium's architecture revolves around the Env class, a high-level Python class that encapsulates the essence of a Markov Decision Process (MDP) as understood in reinforcement learning theory. Although it does not capture every nuance of MDPs, the Env class provides essential functionalities: generating initial states, handling state transitions based on agent actions, and offering visualization capabilities through rendering.
Figure 4: Gymnasium project of Farama Foundation.
At the heart of Gymnasium are four key functions that define the agent-environment interaction loop: make(), Env.reset(), Env.step(), and Env.render(). The make() function is used to instantiate a specific environment, providing a straightforward way to select from the multitude of available tasks. Once an environment is created, Env.reset() initializes it to a starting state, preparing it for a new episode. The Env.step(action) function allows the agent to take an action within the environment, resulting in a transition to a new state, the receipt of a reward, and a flag indicating whether the episode has terminated. Finally, Env.render() offers a visualization of the current state of the environment, which is invaluable for debugging and monitoring the agent’s performance.
Complementing the Env class are various Wrapper classes that enhance and modify the environment's behavior without altering its core functionalities. These wrappers can modify observations, rewards, and actions, providing flexibility for preprocessing and feature extraction, which are crucial for developing sophisticated RL agents. Gymnasium's design emphasizes modularity and extensibility, allowing researchers and developers to easily augment environments to suit their specific needs.
In the context of reinforcement learning, Gymnasium embodies the classic "agent-environment loop." This fundamental concept illustrates how an agent interacts with its environment: the agent receives an observation about the current state of the environment, selects an action based on this observation, and then the environment responds by transitioning to a new state and providing a corresponding reward. This cycle continues iteratively until the environment signals termination, marking the end of an episode. Gymnasium's intuitive API facilitates this interaction loop, making it an essential tool for experimenting with and advancing RL algorithms. By leveraging Gymnasium, researchers can focus on developing and refining their RL models, confident in the library's ability to handle the complexities of environment management and interaction.
Recently, gymnasium_rs is a promosing and evolving project that aims to provide a pure Rust implementation of the Gymnasium API, the widely recognized framework for reinforcement learning (RL) environments originally developed in Python. By mirroring the Gymnasium interface, gymnasium_rs seeks to offer Rust developers a familiar and efficient toolkit for designing, interacting with, and managing RL environments, leveraging Rust's performance, safety, and concurrency advantages. This implementation ensures compatibility and interoperability with the existing Python-based Gymnasium environments, enabling seamless integration between Rust and Python ecosystems. Through features such as compatibility wrappers and standardized API functions (make(), reset(), step(), and render()), gymnasium_rs facilitates the use of established Gymnasium environments like CartPole, MountainCar, and Atari within Rust applications. Additionally, it supports the creation of custom environments, allowing researchers and developers to build and experiment with RL algorithms in Rust while maintaining the ability to utilize Python’s extensive RL libraries and tools. Although still a work in progress, gymnasium_rs is progressively enhancing its feature set, addressing compatibility issues, and optimizing performance to provide a robust foundation for Rust-based RL projects. By bridging the gap between Rust’s systems-level capabilities and Gymnasium’s comprehensive RL environment suite, gymnasium_rs holds the promise of empowering Rust developers to harness the full potential of reinforcement learning with the added benefits of Rust’s safety and efficiency. For more information and to contribute to the development of gymnasium_rs, you can visit the project repository on GitHub: https://github.com/AndrejOrsula/gymnasium_rs.
[dependencies]
gymnasium-rs = "0.1.0"
use gymnasium::{
space::SpaceSampleUniform, Env, GymnasiumResult, PythonEnv, PythonEnvConfig, RenderMode,
};
fn main() -> GymnasiumResult<()> {
let mut env = PythonEnv::<f32>::new(PythonEnvConfig {
env_id: "LunarLanderContinuous-v2".to_string(),
render_mode: RenderMode::Human,
seed: None,
})?;
let mut rng = rand::SeedableRng::from_entropy();
let _reset_return = env.reset();
for _ in 0..1000 {
let action = env.action_space().sample(&mut rng);
let step_return = env.step(action);
if step_return.terminated || step_return.truncated {
let _reset_return = env.reset();
}
}
env.close();
Ok(())
}
The provided Rust code utilizes the gymnasium crate to interact with the "LunarLanderContinuous-v2" environment, a continuous-action reinforcement learning (RL) task where an agent controls a lander to safely touch down on the lunar surface. The main function initializes a PythonEnv with human-rendering mode enabled, allowing visual observation of the environment's state. A random number generator (rng) is seeded using entropy to ensure diverse action sampling. After resetting the environment to obtain the initial state, the code enters a loop that runs for up to 1000 steps. In each iteration, it samples a random action uniformly from the environment's action space and applies this action using the env.step(action) method, which returns the new state, reward, and termination flags. If the episode terminates either by reaching a goal (terminated) or by truncation (truncated), the environment is reset to start a new episode. After completing the loop, the environment is properly closed to release any associated resources. This example demonstrates a fundamental RL interaction loop in Rust, where random actions are taken without any learning strategy, serving as a baseline or a starting point for integrating more sophisticated RL algorithms.
20.3. Conceptual Abstractions in Gym and Gymnasium
Reinforcement learning thrives on the structured interplay between agents and environments. This interaction hinges on a standardized interface that abstracts the complexities of diverse tasks while enabling researchers and practitioners to focus on developing and testing algorithms. OpenAI Gym and its successor, Farama Gymnasium, exemplify this philosophy by providing a robust API for environment interaction. At its core, this API standardizes how agents perceive the environment (via observations), take actions, and receive feedback (rewards and next states). By offering a unified structure, these frameworks democratize RL research, making it accessible to both newcomers and experts while fostering interoperability across projects and tools.
The foundation of these abstractions lies in the concepts of observation and action spaces, which encapsulate the range of inputs and outputs for an agent. An observation space defines the structure and type of data an agent perceives from the environment, such as continuous sensor readings, images, or discrete state labels. Similarly, the action space specifies the set of permissible actions the agent can perform, ranging from discrete choices (e.g., "move left" or "move right") to continuous controls (e.g., "apply force of magnitude 3.5"). These spaces are mathematically defined using properties like dimensionality, bounds, and type (discrete or continuous). For example, in Gym, the Box class models continuous spaces with bounds, while the Discrete class represents a finite set of choices. These abstractions simplify the design of RL algorithms by clearly delineating the range of possible states and actions, reducing ambiguity, and ensuring consistency across environments.
Conceptually, the standardized API and abstractions in Gym and Gymnasium facilitate modularity and interoperability. The reset method initializes the environment and returns the first observation, while the step(action) method executes an action, returning a tuple consisting of the next observation, the received reward, a boolean flag indicating whether the episode has ended, and additional metadata. This simplicity allows RL algorithms to interact seamlessly with a wide range of environments without requiring environment-specific customizations. Moreover, the API supports modularity through wrappers, which extend functionality without altering the core environment. Wrappers can modify observations, rewards, or actions, enabling advanced features like reward shaping, frame stacking for image inputs, or action normalization. By decoupling algorithms from environment-specific details, these abstractions empower researchers to experiment and iterate efficiently.
Mathematically, the abstractions align with the Markov Decision Process (MDP) framework. For a given environment state $s$, an agent selects an action $a$ from the action space $A(s)$. The environment transitions to a new state $s'$ according to a transition probability $P(s' | s, a)$, and the agent receives a reward $r$ defined by the reward function $R(s, a)$. The observation space $O$ encapsulates the partial or full information about the state $s$ that the agent perceives. In Gym and Gymnasium, these components are abstracted as Python classes, making it easier to define, manipulate, and query the properties of the MDP.
For practical implementation, consider the example of creating a simple custom environment using Gym’s API. The environment will simulate a cart moving in a one-dimensional space, where the goal is to reach a target position. Following this, we’ll use Gymnasium wrappers to enhance functionality, such as normalizing rewards or augmenting observations.
The RobustCartPoleEnv is a sophisticated custom gym environment that simulates a cart's movement in a constrained space, designed to provide a challenging yet controlled problem for reinforcement learning algorithms. This environment models a cart that must navigate towards a predefined target position while managing its velocity and position within specified boundaries. Unlike traditional cart-pole environments that focus on balancing, this simulation emphasizes precise movement and strategic navigation, making it an ideal testbed for training agents to develop nuanced movement strategies through trial and error.
# Copy this Python code to Google Colab for testing....
import gym
from gym import spaces
import numpy as np
import warnings
class RobustCartPoleEnv(gym.Env):
"""
A more comprehensive and robust custom gym environment
simulating a cart moving towards a target.
Key Improvements:
- Enhanced state representation
- More complex reward function
- Configurable parameters
- Improved error handling
- Physical constraints
"""
def __init__(self,
min_position=-10.0,
max_position=10.0,
target_position=5.0,
max_steps=200,
noise_std=0.1):
"""
Initialize the environment with configurable parameters.
Args:
min_position (float): Minimum cart position
max_position (float): Maximum cart position
target_position (float): Target position to reach
max_steps (int): Maximum number of steps per episode
noise_std (float): Standard deviation of observation noise
"""
super(RobustCartPoleEnv, self).__init__()
# Validate input parameters
if min_position >= max_position:
raise ValueError("min_position must be less than max_position")
# Define observation and action spaces
self.min_position = min_position
self.max_position = max_position
self.target_position = target_position
self.max_steps = max_steps
self.noise_std = noise_std
# Observation space includes position and velocity
self.observation_space = spaces.Box(
low=np.array([min_position, -np.inf]),
high=np.array([max_position, np.inf]),
dtype=np.float32
)
# Discrete action space (left, stay, right)
self.action_space = spaces.Discrete(3)
# Tracking variables
self.current_step = 0
self.state = None
# Rendering setup
self.render_mode = None
def reset(self, seed=None, options=None):
"""
Reset the environment to a new initial state.
Returns:
np.ndarray: Initial observation
dict: Additional info
"""
super().reset(seed=seed)
# Random initial position and zero initial velocity
self.state = np.array([
self.np_random.uniform(self.min_position, self.max_position),
0.0 # Initial velocity
], dtype=np.float32)
self.current_step = 0
# Add optional observation noise
noisy_state = self.state + self.np_random.normal(0, self.noise_std, size=2)
return noisy_state, {}
def step(self, action):
"""
Execute one time step in the environment.
Args:
action (int): Action to take (0: left, 1: stay, 2: right)
Returns:
tuple: (observation, reward, terminated, truncated, info)
"""
if not self.action_space.contains(action):
warnings.warn(f"Invalid action {action}. Defaulting to 'stay'.")
action = 1
# Update position based on action
velocity_change = {
0: -1.0, # Move left
1: 0.0, # Stay
2: 1.0 # Move right
}[action]
# Update state with simple physics model
new_position = np.clip(
self.state[0] + velocity_change,
self.min_position,
self.max_position
)
new_velocity = new_position - self.state[0]
self.state = np.array([new_position, new_velocity], dtype=np.float32)
# Compute reward with multiple components
distance_to_target = abs(new_position - self.target_position)
proximity_reward = 1.0 / (1 + distance_to_target)
velocity_penalty = abs(new_velocity) * 0.1
reward = proximity_reward - velocity_penalty
# Check termination conditions
terminated = distance_to_target < 0.1
truncated = self.current_step >= self.max_steps
self.current_step += 1
# Add noise to observation
noisy_state = self.state + self.np_random.normal(0, self.noise_std, size=2)
return noisy_state, reward, terminated, truncated, {
'distance_to_target': distance_to_target,
'velocity': new_velocity
}
def render(self, mode='human'):
"""
Render the current environment state.
Args:
mode (str): Rendering mode
"""
if mode == 'human':
print(f"Cart Position: {self.state[0]:.2f}, "
f"Velocity: {self.state[1]:.2f}, "
f"Target: {self.target_position:.2f}")
else:
warnings.warn(f"Render mode {mode} not supported.")
def close(self):
"""
Clean up the environment.
"""
pass
def test_robust_cart_env():
"""
Demonstrate the usage of the RobustCartPoleEnv.
"""
env = RobustCartPoleEnv()
# Test reset
state, _ = env.reset()
print("Initial State:", state)
# Test multiple steps
for step in range(20):
# Randomly sample an action
action = env.action_space.sample()
# Take a step
next_state, reward, terminated, truncated, info = env.step(action)
# Render current state
env.render()
# Check if episode is over
if terminated or truncated:
print(f"Episode finished after {step+1} steps")
break
if __name__ == "__main__":
test_robust_cart_env()
The environment operates by allowing an agent to take discrete actions (move left, stay, or move right) that influence the cart's position and velocity. With each action, the cart's state updates based on a simple physics model that clips its movement within predefined minimum and maximum position bounds. The agent receives a reward function that balances proximity to the target and penalizes excessive velocity, creating a complex optimization problem. The environment introduces realistic elements like observation noise and tracks both position and velocity, requiring the learning agent to develop robust navigation strategies that account for imperfect sensing and movement constraints.
OpenAI Gym is a pioneering toolkit in reinforcement learning that provides a standardized interface for developing, comparing, and benchmarking learning algorithms across diverse problem domains. By defining a consistent API with methods like reset(), step(), and standardized observation_space and action_space attributes, Gym enables researchers and developers to apply identical learning algorithms to multiple environments. This abstraction allows machine learning practitioners to focus on algorithm development rather than environment-specific implementation details, promoting reproducibility and accelerating research in areas like robotics, game playing, and autonomous systems.
Now lets learn Gymnasium framework. The provided Python code leverages the Gymnasium to create and interact with an enhanced version of the classic CartPole environment, named RobustCartPoleEnv. This custom environment extends Gymnasium’s Env class to offer comprehensive state and reward modeling, incorporating continuous action spaces and explicitly defined observation boundaries. By integrating multiple advanced wrappers such as NormalizeReward, TimeLimit, RecordEpisodeStatistics, and ClipAction, the code enhances the base environment's functionality, enabling more sophisticated reward scaling, action constraints, episode termination handling, and performance tracking. Additionally, the implementation includes a demonstration of both single and vectorized environment interactions, showcasing how multiple instances of the environment can be managed concurrently using Gymnasium’s SyncVectorEnv. This setup not only provides a robust framework for reinforcement learning experiments but also ensures compatibility with existing Gymnasium-compatible tools and workflows.
# Copy and paste to Google colab for test ...
import gymnasium as gym
import numpy as np
from gymnasium import spaces
from gymnasium.wrappers import (
NormalizeReward,
TimeLimit,
RecordEpisodeStatistics,
ClipAction
)
from gymnasium.vector import SyncVectorEnv
class RobustCartPoleEnv(gym.Env):
"""
Enhanced Gymnasium-compatible cart environment
with comprehensive state and reward modeling.
"""
def __init__(
self,
min_position=-10.0,
max_position=10.0,
target_position=5.0,
max_steps=200
):
super().__init__()
# Ensure float32 typing for spaces
min_position = np.float32(min_position)
max_position = np.float32(max_position)
# Observation and action spaces with explicit float32
self.observation_space = spaces.Box(
low=np.array([min_position, np.float32(-np.inf)], dtype=np.float32),
high=np.array([max_position, np.float32(np.inf)], dtype=np.float32),
dtype=np.float32
)
# Change action space to Box for wrapper compatibility
self.action_space = spaces.Box(
low=np.float32(-1.0),
high=np.float32(1.0),
shape=(1,),
dtype=np.float32
)
# Environment parameters
self.min_position = min_position
self.max_position = max_position
self.target_position = np.float32(target_position)
self.max_steps = max_steps
# State tracking
self.state = None
self.steps = 0
def reset(self, seed=None, options=None):
"""
Reset the environment with optional seed and options.
Returns:
observation (np.ndarray): Initial state
info (dict): Additional information
"""
super().reset(seed=seed)
# Random initial state with float32
self.state = np.array([
self.np_random.uniform(self.min_position, self.max_position),
np.float32(0.0) # Initial velocity
], dtype=np.float32)
self.steps = 0
return self.state, {}
def step(self, action):
"""
Execute one timestep in the environment.
Returns:
observation, reward, terminated, truncated, info
"""
# Convert continuous action to discrete-like movement
action = np.clip(action[0], -1, 1)
velocity_change = np.float32(action)
# Update position based on action
new_position = np.clip(
self.state[0] + velocity_change,
self.min_position,
self.max_position
)
new_velocity = new_position - self.state[0]
self.state = np.array([new_position, new_velocity], dtype=np.float32)
self.steps += 1
# Compute reward
distance_to_target = abs(new_position - self.target_position)
reward = np.float32(1 / (1 + distance_to_target))
# Check termination conditions
terminated = distance_to_target < 0.1
truncated = self.steps >= self.max_steps
return self.state, reward, terminated, truncated, {}
def create_env_with_wrappers():
"""
Create a Gymnasium environment with multiple advanced wrappers.
Returns:
gym.Env: Fully wrapped environment
"""
# Create base environment
base_env = RobustCartPoleEnv()
# Apply multiple wrappers
wrapped_env = gym.wrappers.RecordEpisodeStatistics(
gym.wrappers.TimeLimit(
gym.wrappers.NormalizeReward(
gym.wrappers.ClipAction(base_env)
),
max_episode_steps=50
)
)
return wrapped_env
def demonstrate_env_interaction():
"""
Demonstrate advanced environment interaction techniques.
"""
# Create environment
env = create_env_with_wrappers()
# Reset environment
state, info = env.reset()
print("Initial State (Wrapped):", state)
# Single environment interaction
for _ in range(20):
# Sample random action (now continuous)
action = env.action_space.sample()
# Step through environment
state, reward, terminated, truncated, info = env.step(action)
print(f"State: {state}, Normalized Reward: {reward}")
# Check episode termination
if terminated or truncated:
print("Episode finished!")
break
# Demonstrate vector environment
vector_env = SyncVectorEnv([create_env_with_wrappers] * 3)
# Batch environment interaction
states, infos = vector_env.reset()
print("\nVector Environment States:", states)
# Batch action sampling and stepping
actions = vector_env.action_space.sample()
next_states, rewards, terminated, truncated, infos = vector_env.step(actions)
print("Vector Environment Next States:", next_states)
if __name__ == "__main__":
demonstrate_env_interaction()
The code begins by defining the RobustCartPoleEnv class, which inherits from Gymnasium’s Env class, and initializes the environment with specific parameters such as position limits, target position, and maximum steps per episode. The reset method initializes the environment’s state with a random position within the defined range and zero velocity, preparing it for a new episode. The step method processes continuous actions by clipping them to a valid range, updating the cart’s position and velocity based on the action, and calculating the reward as an inverse function of the distance to the target position. It also checks for termination conditions, either by achieving proximity to the target or exceeding the maximum number of steps. The create_env_with_wrappers function applies a series of wrappers to the base environment, enhancing its capabilities by normalizing rewards, enforcing action clipping, limiting episode duration, and recording episode statistics. The demonstrate_env_interaction function showcases how to interact with both single and multiple wrapped environments, performing actions, stepping through the environment, and handling episode terminations, thereby illustrating the practical application of the enhanced environment in reinforcement learning workflows.
Compared to the original OpenAI Gym framework, Gymnasium offers a more maintained and actively developed alternative, ensuring better compatibility and extended features for modern reinforcement learning applications. While Gym provides a foundational API for RL environments, Gymnasium builds upon this by introducing additional utilities and wrappers that facilitate more complex and nuanced interactions, such as advanced reward normalization and action clipping mechanisms demonstrated in the provided code. Furthermore, Gymnasium’s support for vectorized environments through tools like SyncVectorEnv allows for more efficient parallel processing and scalability, which is essential for training more sophisticated RL agents. The compatibility wrapper in Gymnasium also ensures that legacy Gym environments remain usable, providing a seamless transition for projects migrating from Gym to Gymnasium. Overall, Gymnasium enhances the usability, flexibility, and performance of the Gym framework, making it a more robust choice for contemporary reinforcement learning research and development.
For a similar example in Rust, the RobustCartPoleEnv implementation is a sophisticated custom gym environment designed to simulate a cart's movement towards a target position. It leverages Rust's powerful type system and performance characteristics, providing a robust alternative to the Python implementation while maintaining the core principles of the original environment. The implementation utilizes the gym-rs crate, ndarray for numerical operations, and the rand crate for stochastic behaviors, creating a flexible and configurable learning environment for reinforcement learning algorithms.
use gym_rs::{
core::{Env, ActionSpace, ObservationSpace},
spaces::{BoxSpace, DiscreteSpace},
};
use ndarray::{Array1, ArrayView1};
use rand::prelude::*;
use std::fmt;
pub struct RobustCartPoleEnv {
min_position: f64,
max_position: f64,
target_position: f64,
max_steps: usize,
noise_std: f64,
current_step: usize,
state: Array1<f64>,
rng: ThreadRng,
}
impl RobustCartPoleEnv {
pub fn new(
min_position: f64,
max_position: f64,
target_position: f64,
max_steps: usize,
noise_std: f64,
) -> Result<Self, String> {
if min_position >= max_position {
return Err("min_position must be less than max_position".to_string());
}
Ok(Self {
min_position,
max_position,
target_position,
max_steps,
noise_std,
current_step: 0,
state: Array1::zeros(2),
rng: thread_rng(),
})
}
}
impl Env for RobustCartPoleEnv {
type Action = usize;
type Observation = Array1<f64>;
fn observation_space(&self) -> ObservationSpace<Self::Observation> {
ObservationSpace::Box(BoxSpace::new(
Array1::from_vec(vec![self.min_position, f64::NEG_INFINITY]),
Array1::from_vec(vec![self.max_position, f64::INFINITY]),
))
}
fn action_space(&self) -> ActionSpace<Self::Action> {
ActionSpace::Discrete(DiscreteSpace::new(3))
}
fn reset(&mut self) -> Self::Observation {
// Random initial position and zero initial velocity
self.state[0] = self.rng.gen_range(self.min_position..=self.max_position);
self.state[1] = 0.0;
self.current_step = 0;
// Add noise to observation
let noise = Array1::from_vec(vec![
self.rng.normal(0.0, self.noise_std),
self.rng.normal(0.0, self.noise_std),
]);
self.state.clone() + &noise
}
fn step(&mut self, action: Self::Action) -> (Self::Observation, f64, bool, bool, Option<String>) {
// Validate action
let action = match action {
0 | 1 | 2 => action,
_ => {
println!("Invalid action {}. Defaulting to 'stay'.", action);
1
}
};
// Update position based on action
let velocity_change = match action {
0 => -1.0, // Move left
1 => 0.0, // Stay
2 => 1.0, // Move right
_ => unreachable!(),
};
// Update state with simple physics model
let new_position = self.state[0] + velocity_change;
let new_position = new_position.clamp(self.min_position, self.max_position);
let new_velocity = new_position - self.state[0];
self.state[0] = new_position;
self.state[1] = new_velocity;
// Compute reward
let distance_to_target = (new_position - self.target_position).abs();
let proximity_reward = 1.0 / (1.0 + distance_to_target);
let velocity_penalty = new_velocity.abs() * 0.1;
let reward = proximity_reward - velocity_penalty;
// Check termination conditions
let terminated = distance_to_target < 0.1;
let truncated = self.current_step >= self.max_steps;
self.current_step += 1;
// Add noise to observation
let noise = Array1::from_vec(vec![
self.rng.normal(0.0, self.noise_std),
self.rng.normal(0.0, self.noise_std),
]);
let noisy_state = self.state.clone() + &noise;
(noisy_state, reward, terminated, truncated, None)
}
}
impl fmt::Display for RobustCartPoleEnv {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
write!(
f,
"Cart Position: {:.2}, Velocity: {:.2}, Target: {:.2}",
self.state[0], self.state[1], self.target_position
)
}
}
// Example usage function
fn test_robust_cart_env() {
let mut env = RobustCartPoleEnv::new(
-10.0, // min_position
10.0, // max_position
5.0, // target_position
200, // max_steps
0.1 // noise_std
).expect("Failed to create environment");
// Test reset
let initial_state = env.reset();
println!("Initial State: {:?}", initial_state);
// Test multiple steps
for step in 0..20 {
// Randomly sample an action using ThreadRng
let action = thread_rng().gen_range(0..3);
// Take a step
let (next_state, reward, terminated, truncated, _) = env.step(action);
// Print current state
println!("Step {}: {}, Reward: {:.2}", step, env, reward);
// Check if episode is over
if terminated || truncated {
println!("Episode finished after {} steps", step + 1);
break;
}
}
}
fn main() {
test_robust_cart_env();
}
This Rust environment extends the basic gym environment interface by introducing enhanced state representation, a complex reward function, and configurable parameters. It features a discrete action space with three possible actions (move left, stay, move right), an observation space representing cart position and velocity, and a sophisticated reward mechanism that balances proximity to the target and velocity penalties. The implementation includes robust error handling, noise injection for observation uncertainty, and a flexible configuration system that allows researchers to fine-tune environment parameters such as position limits, target position, maximum steps, and observation noise.
While the Rust implementation closely mirrors the Python gym environment, there are subtle differences in implementation that may require careful consideration when transitioning between platforms. The gym-rs crate attempts to provide a similar interface to Python's gym, but developers should anticipate potential variations in random number generation, type handling, and specific trait implementations. For seamless cross-language reinforcement learning experiments, additional wrapper code or careful parameter matching might be necessary to ensure consistent behavior between Python and Rust environments.
Now lets see other implementation using Rust’s gymnasium crate. The gymnasium-rs implementation of the RobustCartPoleEnv is a sophisticated reinforcement learning environment that simulates a cart moving along a one-dimensional space with the goal of reaching a target position. Unlike traditional CartPole environments, this version introduces more nuanced state management, continuous action spaces, and flexible reward mechanisms. It demonstrates Rust's capabilities in creating performant and type-safe reinforcement learning simulation environments, leveraging the gymnasium-rs crate to provide a similar interface to Python's Gymnasium library.
[dependencies]
gymnasium-rs = "0.1.0" # Use the latest version
ndarray = "0.15.6"
rand = "0.8.5"
use gymnasium_rs::{
Env,
EnvResult,
Space,
BoxSpace,
ActionSpace,
ResetMode,
StepResult,
};
use ndarray::{Array1, ArrayView1};
use rand::Rng;
use std::sync::Arc;
/// A robust CartPole environment with enhanced state and reward modeling
pub struct RobustCartPoleEnv {
min_position: f32,
max_position: f32,
target_position: f32,
max_steps: usize,
current_state: Array1<f32>,
steps: usize,
rng: rand::rngs::ThreadRng,
}
impl RobustCartPoleEnv {
pub fn new(
min_position: f32,
max_position: f32,
target_position: f32,
max_steps: usize
) -> Self {
Self {
min_position,
max_position,
target_position,
max_steps,
current_state: Array1::zeros(2),
steps: 0,
rng: rand::thread_rng(),
}
}
}
impl Env for RobustCartPoleEnv {
fn observation_space(&self) -> Space {
Space::Box(BoxSpace::new(
Array1::from_vec(vec![self.min_position, f32::NEG_INFINITY]),
Array1::from_vec(vec![self.max_position, f32::INFINITY]),
))
}
fn action_space(&self) -> ActionSpace {
ActionSpace::Box(BoxSpace::new(
Array1::from_vec(vec![-1.0]),
Array1::from_vec(vec![1.0]),
))
}
fn reset(&mut self, _mode: Option<ResetMode>) -> EnvResult {
// Random initial position within defined range
let initial_position = self.rng.gen_range(self.min_position..=self.max_position);
self.current_state = Array1::from_vec(vec![
initial_position,
0.0 // Initial velocity
]);
self.steps = 0;
EnvResult {
observation: self.current_state.to_owned(),
info: Default::default(),
}
}
fn step(&mut self, action: ArrayView1<f32>) -> StepResult {
// Clip and apply action
let velocity_change = action[0].clamp(-1.0, 1.0);
// Update position with action
let new_position = (self.current_state[0] + velocity_change)
.clamp(self.min_position, self.max_position);
let new_velocity = new_position - self.current_state[0];
// Update state
self.current_state[0] = new_position;
self.current_state[1] = new_velocity;
self.steps += 1;
// Compute reward based on distance to target
let distance_to_target = (new_position - self.target_position).abs();
let reward = 1.0 / (1.0 + distance_to_target);
// Check termination conditions
let terminated = distance_to_target < 0.1;
let truncated = self.steps >= self.max_steps;
StepResult {
observation: self.current_state.to_owned(),
reward,
terminated,
truncated,
info: Default::default(),
}
}
}
/// Demonstrate environment interaction
fn main() {
// Create base environment
let mut env = RobustCartPoleEnv::new(
-10.0, // min_position
10.0, // max_position
5.0, // target_position
200 // max_steps
);
// Reset environment
let reset_result = env.reset(None);
println!("Initial State: {:?}", reset_result.observation);
// Interact with environment
for _ in 0..20 {
// Sample a random action
let action = Array1::from_vec(vec![rand::thread_rng().gen_range(-1.0..=1.0)]);
// Step through environment
let step_result = env.step(action.view());
println!(
"State: {:?}, Reward: {:.4}, Terminated: {}, Truncated: {}",
step_result.observation,
step_result.reward,
step_result.terminated,
step_result.truncated
);
// Check episode termination
if step_result.terminated || step_result.truncated {
println!("Episode finished!");
break;
}
}
}
The environment operates by maintaining a two-dimensional state vector representing the cart's position and velocity. During each step, an agent can apply a continuous action (-1 to 1) that influences the cart's movement. The environment responds by updating the cart's position, calculating a reward based on proximity to a target position, and determining whether the episode has terminated. The reward function is designed to encourage the agent to approach the target position, with rewards inversely proportional to the distance from the target. Termination occurs either when the cart is very close to the target (within 0.1 units) or when the maximum number of steps is reached.
Compared to the Python versions of Gym and Gymnasium, Rust implementations offer superior performance, stronger type safety, and more explicit memory management. While the Python libraries rely on dynamic typing and NumPy’s flexible array operations, Rust versions utilize ndarray with explicit type conversions and compile-time checks. The Rust implementations feature more predictable memory usage and the potential for better runtime performance. However, they require more explicit type handling and lack the immediate readability provided by Python’s dynamic typing. Additionally, Rust code for Gym environments is still experimental and a work in progress, meaning some components may not be stable. The effort to port Gym and Gymnasium from Python to Rust demonstrates Rust’s capability to create low-level, efficient reinforcement learning environments with expressiveness comparable to Python, albeit with a steeper learning curve and more verbose type declarations.
As summary, the abstractions provided by OpenAI Gym and Farama Gymnasium establish a unified framework for interacting with RL environments. By standardizing the API and leveraging observation and action spaces, these tools abstract away environment-specific complexities, fostering modularity and interoperability. The inclusion of wrappers further enhances functionality, enabling seamless integration of advanced features like reward normalization and observation preprocessing. Through practical examples in Python and Rust, we demonstrate the power and flexibility of these abstractions, underscoring their value in advancing reinforcement learning research and applications.
20.4. Practical Implementation in Python
Python serves as an excellent starting point for reinforcement learning due to its extensive ecosystem of libraries and frameworks. Creating a custom Gym environment in Python is a fundamental step in understanding how RL environments work. The process begins with defining observation and action spaces, which describe the data structures that represent what the agent perceives and the actions it can perform. Gym’s spaces module provides robust tools for defining these spaces, supporting both discrete and continuous domains.
The observation space represents the data the agent receives from the environment, such as positions, velocities, or sensor readings. For example, a continuous observation space can be defined using the Box class, which specifies bounds and dimensions. The action space, conversely, defines the set of all possible actions. For example, a discrete action space might represent left and right movements, while a continuous space could represent forces or velocities. Structuring these spaces carefully ensures that the environment is intuitive and compatible with RL algorithms.
When designing environments, best practices include ensuring simplicity, clarity, and scalability. The reset method initializes the environment and returns the initial observation, while the step method defines the core dynamics: it processes an action, updates the state, computes rewards, and signals episode termination. Clear code organization, modularity, and the use of comments are essential to maintainability and reusability. For instance, encapsulating state updates and reward logic within helper functions can enhance clarity.
Below is a complete Python example for a custom Gym environment simulating a balancing pole. The example includes connecting the environment to a simple Deep Q-Network agent. The integration of the DQN with the OpenAI Gym framework provides a powerful combination for developing and testing reinforcement learning algorithms. DQN, a pioneering algorithm in deep reinforcement learning, leverages neural networks to approximate the optimal action-value function, enabling agents to make informed decisions in complex environments. OpenAI Gym serves as a comprehensive toolkit that offers a wide array of standardized environments, facilitating the development, benchmarking, and comparison of various reinforcement learning algorithms, including DQN. By utilizing Gym's well-defined interfaces and diverse set of environments, developers can efficiently implement and evaluate DQN agents across different tasks, ranging from simple control problems to intricate simulations.
"""
Balancing Pole Environment with DQN Training and Monitoring.
This script defines a custom Gym environment for balancing a pole on a cart,
implements a Deep Q-Network (DQN) agent using stable-baselines3, and includes
a custom callback to monitor and print learning progress.
Dependencies:
- gym
- numpy
- pygame
- stable-baselines3
- shimmy>=2.0
To install the dependencies, run:
pip install stable-baselines3 'shimmy>=2.0' gym numpy pygame
Usage:
python balancing_pole_env_with_dqn.py
"""
import sys
import time
import gym
from gym import spaces
from gym.utils import seeding
import numpy as np
import pygame
from pygame import gfxdraw
# Import stable_baselines3 and necessary components
from stable_baselines3 import DQN
from stable_baselines3.common.callbacks import BaseCallback
class BalancingPoleEnv(gym.Env):
"""
A more advanced and robust environment for balancing a pole on a cart.
This environment follows the OpenAI Gym interface and includes realistic physics,
rendering, and reproducibility features.
"""
metadata = {
"render.modes": ["human", "rgb_array"],
"video.frames_per_second": 50
}
def __init__(self, render_mode=None):
super(BalancingPoleEnv, self).__init__()
# Define action and observation space
# Actions: Push cart left or right
self.action_space = spaces.Discrete(2)
# Observations: Cart Position, Cart Velocity, Pole Angle, Pole Angular Velocity
high = np.array([2.4, np.finfo(np.float32).max, np.pi, np.finfo(np.float32).max],
dtype=np.float32)
self.observation_space = spaces.Box(-high, high, dtype=np.float32)
# Physics parameters
self.gravity = 9.8 # Acceleration due to gravity
self.masscart = 1.0 # Mass of the cart
self.masspole = 0.1 # Mass of the pole
self.total_mass = self.masscart + self.masspole
self.length = 0.5 # Half-length of the pole
self.polemass_length = self.masspole * self.length
self.force_mag = 10.0 # Magnitude of the force applied to the cart
self.tau = 0.02 # Time step for simulation
# Episode parameters
self.max_steps = 200 # Maximum number of steps per episode
self.current_step = 0
# Rendering parameters
self.render_mode = render_mode
self.screen = None
self.clock = None
self.screen_width = 600
self.screen_height = 400
self.cart_width = 50
self.cart_height = 30
self.pole_length_px = 100 # Length of the pole in pixels
self.cart_color = (0, 0, 0) # Black
self.pole_color = (255, 0, 0) # Red
self.background_color = (255, 255, 255) # White
# Initialize state
self.state = None
# For reproducibility
self.seed()
def seed(self, seed=None):
"""
Sets the seed for this environment's random number generator(s).
Args:
seed (int, optional): The seed value.
Returns:
list: A list containing the seed.
"""
self.np_random, seed = seeding.np_random(seed)
return [seed]
def reset(self, seed=None, options=None):
"""
Resets the environment to an initial state and returns an initial observation.
Args:
seed (int, optional): The seed value.
options (dict, optional): Additional options.
Returns:
tuple: A tuple containing the initial observation and an empty info dictionary.
"""
super().reset(seed=seed)
# Initialize state with small random values
self.state = self.np_random.uniform(low=-0.05, high=0.05, size=(4,))
self.current_step = 0
return np.array(self.state, dtype=np.float32), {}
def step(self, action):
"""
Executes one time step within the environment.
Args:
action (int): The action to take (0 for left, 1 for right).
Returns:
tuple: A tuple containing:
- observation (np.ndarray): The next observation.
- reward (float): The reward obtained from taking the action.
- done (bool): Whether the episode has ended.
- truncated (bool): Whether the episode was truncated.
- info (dict): Additional information.
"""
assert self.action_space.contains(action), f"{action} is an invalid action"
x, x_dot, theta, theta_dot = self.state
force = self.force_mag if action == 1 else -self.force_mag
costheta = np.cos(theta)
sintheta = np.sin(theta)
# Dynamics equations based on the cart-pole system
temp = (force + self.polemass_length * theta_dot ** 2 * sintheta) / self.total_mass
theta_acc = (self.gravity * sintheta - costheta * temp) / \
(self.length * (4.0/3.0 - self.masspole * costheta ** 2 / self.total_mass))
x_acc = temp - self.polemass_length * theta_acc * costheta / self.total_mass
# Update the state using Euler's method
x = x + self.tau * x_dot
x_dot = x_dot + self.tau * x_acc
theta = theta + self.tau * theta_dot
theta_dot = theta_dot + self.tau * theta_acc
self.state = np.array([x, x_dot, theta, theta_dot], dtype=np.float32)
# Check termination conditions
done = bool(
x < -2.4
or x > 2.4
or theta < -12 * np.pi / 180
or theta > 12 * np.pi / 180
or self.current_step >= self.max_steps
)
reward = 1.0 if not done else 0.0
self.current_step += 1
truncated = self.current_step >= self.max_steps
info = {}
return self.state, reward, done, truncated, info
def render(self, mode="human"):
"""
Renders the environment.
Args:
mode (str): The mode to render with. Supports "human" and "rgb_array".
"""
if self.render_mode is None:
return
if self.screen is None:
pygame.init()
pygame.display.init()
if self.render_mode == "human":
self.screen = pygame.display.set_mode((self.screen_width, self.screen_height))
elif self.render_mode == "rgb_array":
self.screen = pygame.Surface((self.screen_width, self.screen_height))
self.clock = pygame.time.Clock()
if self.state is None:
return
x, _, theta, _ = self.state
# Convert to pixel coordinates
cart_x = self.screen_width // 2 + int(x * 100) # Scale position
cart_y = self.screen_height // 2
pole_end_x = cart_x + int(self.pole_length_px * np.sin(theta))
pole_end_y = cart_y - int(self.pole_length_px * np.cos(theta))
for event in pygame.event.get():
if event.type == pygame.QUIT:
self.close()
sys.exit()
self.screen.fill(self.background_color) # Fill background
# Draw cart
cart_rect = pygame.Rect(0, 0, self.cart_width, self.cart_height)
cart_rect.center = (cart_x, cart_y)
pygame.draw.rect(self.screen, self.cart_color, cart_rect)
# Draw pole
pygame.draw.line(self.screen, self.pole_color, (cart_x, cart_y),
(pole_end_x, pole_end_y), 5)
# Optionally, draw a base
base_width = 100
base_height = 10
base_rect = pygame.Rect(0, 0, base_width, base_height)
base_rect.center = (self.screen_width // 2, cart_y + self.cart_height // 2 + base_height)
pygame.draw.rect(self.screen, (0, 0, 0), base_rect)
# Update the display
if self.render_mode == "human":
pygame.display.flip()
self.clock.tick(self.metadata["video.frames_per_second"])
elif self.render_mode == "rgb_array":
# Return RGB array if needed
return np.array(pygame.surfarray.pixels3d(self.screen))
def close(self):
"""
Performs any necessary cleanup.
"""
if self.screen is not None:
pygame.display.quit()
pygame.quit()
self.screen = None
self.clock = None
class EpisodeRewardCallback(BaseCallback):
"""
Custom callback for printing the reward after each episode.
"""
def __init__(self, verbose=0):
super(EpisodeRewardCallback, self).__init__(verbose)
self.episode_rewards = []
self.current_rewards = 0.0
def _on_step(self) -> bool:
# Retrieve information about the current step
done_array = self.locals.get('dones')
reward_array = self.locals.get('rewards')
if done_array is not None:
for done, reward in zip(done_array, reward_array):
self.current_rewards += reward
if done:
self.episode_rewards.append(self.current_rewards)
print(f"Episode {len(self.episode_rewards)}: Reward = {self.current_rewards}")
self.current_rewards = 0.0
return True # Returning False stops training
def main():
# Create the environment
env = BalancingPoleEnv(render_mode=None) # Set to "human" to visualize
# Initialize the DQN agent
model = DQN(
"MlpPolicy",
env,
verbose=1,
learning_rate=1e-3,
buffer_size=10000,
learning_starts=1000,
batch_size=32,
gamma=0.99,
train_freq=4,
target_update_interval=1000,
exploration_fraction=0.1,
exploration_final_eps=0.02,
)
# Create the callback for monitoring
callback = EpisodeRewardCallback()
# Train the agent
print("Starting training...")
model.learn(total_timesteps=100000, callback=callback)
print("Training completed.")
# Save the trained model
model.save("dqn_balancing_pole")
print("Model saved as 'dqn_balancing_pole'.")
# Load the trained model (optional)
# model = DQN.load("dqn_balancing_pole", env=env)
# Evaluate the trained agent
print("Starting evaluation...")
env.render_mode = "human" # Enable rendering for evaluation
obs, _ = env.reset()
done = False
total_reward = 0.0
try:
while not done:
# Predict the action using the trained model
action, _states = model.predict(obs, deterministic=True)
obs, reward, done, truncated, info = env.step(action)
total_reward += reward
env.render(mode="human") # Render the environment
time.sleep(env.tau) # Sync with the simulation time step
except KeyboardInterrupt:
print("Interrupted by user.")
finally:
env.close()
print(f"Evaluation completed. Total Reward: {total_reward}")
if __name__ == "__main__":
main()
The provided code exemplifies the seamless integration of a custom Gym environment, BalancingPoleEnv, with a DQN agent using the stable-baselines3 library. The BalancingPoleEnv simulates a cart-pole system where the objective is to balance a pole on a moving cart by applying discrete left or right forces. The environment adheres to Gym's API standards, defining action and observation spaces, implementing realistic physics, and incorporating rendering capabilities through Pygame. The DQN agent is initialized with specific hyperparameters and trained over a defined number of timesteps, during which a custom callback monitors and prints episode rewards to track learning progress. After training, the agent is evaluated in the environment with visual rendering enabled, allowing for an assessment of its performance in maintaining the pole's balance. This structured approach ensures that the DQN agent effectively learns to interact with the environment, optimizing its policy based on the rewards received from successfully balancing the pole.
Leveraging Gym and Pygame significantly enhances the implementation and development of DQN agents by providing robust tools for environment simulation and visualization. Gym's standardized interface allows for easy experimentation and scalability, enabling developers to switch between different environments without altering the core reinforcement learning algorithms. This flexibility is crucial for testing the generalizability and robustness of DQN agents across varied tasks. Meanwhile, Pygame facilitates real-time rendering of the environment, offering visual feedback that is invaluable for debugging and understanding the agent's decision-making process. By observing the agent's interactions within a visually rendered environment, developers can gain deeper insights into the agent's behavior, identify potential issues, and fine-tune hyperparameters more effectively. Together, Gym and Pygame create an interactive and versatile ecosystem that not only streamlines the development of advanced reinforcement learning models like DQN but also enriches the overall learning and debugging experience.
Lets learn a more complex RL model to implement the Multi-Agent Deep Deterministic Policy Gradient (MADDPG) algorithm within the Gymnasium framework using PyTorch. MADDPG extends the Deep Deterministic Policy Gradient (DDPG) method to environments with multiple agents, allowing each agent to learn its policy while considering the policies of other agents. Gymnasium, as an advanced successor to OpenAI Gym, provides a flexible and standardized interface for defining and interacting with environments, facilitating seamless integration with MARL algorithms. PyTorch, renowned for its dynamic computation graph and ease of use, serves as an excellent foundation for implementing the neural networks and optimization routines required by MADDPG. Together, these frameworks enable the development of sophisticated multi-agent systems capable of learning and adapting in dynamic and interactive environments.
The provided code demonstrates a comprehensive implementation of the MADDPG algorithm using Gymnasium and PyTorch. It defines a custom multi-agent environment where multiple agents control separate cart-pole systems, each aiming to balance its pole while potentially interacting with others. The MADDPGAgent class encapsulates the actor and critic networks for each agent, handling action selection, policy updates, and target network synchronization. The ReplayBuffer class manages experience storage, facilitating efficient sampling for training. The main training loop orchestrates interactions between agents and the environment, collects experiences, updates policies based on sampled experiences, and periodically evaluates agent performance. Additionally, the code includes mechanisms for monitoring training progress, such as printing episode rewards and optionally rendering the environment for visual inspection. This structured approach ensures that each agent learns to optimize its policy in a coordinated manner, leveraging the strengths of Gymnasium's environment management and PyTorch's deep learning capabilities.
"""
Multi-Agent Deep Deterministic Policy Gradient (MADDPG) Implementation using Gymnasium and PyTorch.
This script defines a custom multi-agent CartPole environment, implements the MADDPG algorithm
using PyTorch, and includes training and evaluation loops. Each agent controls its own CartPole
system, aiming to balance the pole while potentially interacting with others.
Dependencies:
- gymnasium
- numpy
- torch
- matplotlib (optional, for plotting rewards)
To install the dependencies, run:
pip install gymnasium numpy torch matplotlib
Usage:
python maddpg_cartpole.py
"""
import gymnasium as gym
from gymnasium import spaces
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import random
from collections import deque
import matplotlib.pyplot as plt
import time
import pygame # Ensure pygame is installed
# Set random seeds for reproducibility
SEED = 42
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
# Hyperparameters
BUFFER_SIZE = int(1e6)
BATCH_SIZE = 1024
GAMMA = 0.95
TAU = 0.01
LR_ACTOR = 1e-4
LR_CRITIC = 1e-3
UPDATE_EVERY = 20
EPSILON_START = 1.0
EPSILON_END = 0.05
EPSILON_DECAY = 1e-5
NUM_EPISODES = 500
MAX_STEPS = 200
# Define the MADDPG Actor Network
class Actor(nn.Module):
def __init__(self, state_size, action_size, hidden_units=128):
super(Actor, self).__init__()
self.fc1 = nn.Linear(state_size, hidden_units)
self.fc2 = nn.Linear(hidden_units, hidden_units)
self.fc3 = nn.Linear(hidden_units, action_size)
self.relu = nn.ReLU()
self.tanh = nn.Tanh() # Assuming action space is continuous and normalized
def forward(self, state):
x = self.relu(self.fc1(state))
x = self.relu(self.fc2(x))
return self.tanh(self.fc3(x))
# Define the MADDPG Critic Network
class Critic(nn.Module):
def __init__(self, total_state_size, total_action_size, hidden_units=128):
super(Critic, self).__init__()
self.fc1 = nn.Linear(total_state_size + total_action_size, hidden_units)
self.fc2 = nn.Linear(hidden_units, hidden_units)
self.fc3 = nn.Linear(hidden_units, 1)
self.relu = nn.ReLU()
def forward(self, states, actions):
x = torch.cat((states, actions), dim=1)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
return self.fc3(x)
# Replay Buffer for storing experiences
class ReplayBuffer:
def __init__(self, buffer_size, batch_size, num_agents):
self.memory = deque(maxlen=buffer_size)
self.batch_size = batch_size
self.num_agents = num_agents
def add(self, states, actions, rewards, next_states, dones):
self.memory.append((states, actions, rewards, next_states, dones))
def sample(self):
experiences = random.sample(self.memory, k=self.batch_size)
states = np.array([exp[0] for exp in experiences], dtype=np.float32)
actions = np.array([exp[1] for exp in experiences], dtype=np.float32)
rewards = np.array([exp[2] for exp in experiences], dtype=np.float32)
next_states = np.array([exp[3] for exp in experiences], dtype=np.float32)
dones = np.array([exp[4] for exp in experiences], dtype=bool)
return states, actions, rewards, next_states, dones
def __len__(self):
return len(self.memory)
# MADDPG Agent
class MADDPGAgent:
def __init__(self, state_size, action_size, num_agents, agent_id, device):
self.state_size = state_size
self.action_size = action_size
self.num_agents = num_agents
self.agent_id = agent_id
self.device = device
# Actor Network
self.actor_local = Actor(state_size, action_size).to(self.device)
self.actor_target = Actor(state_size, action_size).to(self.device)
self.actor_optimizer = optim.Adam(self.actor_local.parameters(), lr=LR_ACTOR)
# Critic Network
total_state_size = state_size * num_agents
total_action_size = action_size * num_agents
self.critic_local = Critic(total_state_size, total_action_size).to(self.device)
self.critic_target = Critic(total_state_size, total_action_size).to(self.device)
self.critic_optimizer = optim.Adam(self.critic_local.parameters(), lr=LR_CRITIC)
# Initialize target networks with the same weights
self.hard_update(self.actor_target, self.actor_local)
self.hard_update(self.critic_target, self.critic_local)
self.epsilon = EPSILON_START
def hard_update(self, target, source):
target.load_state_dict(source.state_dict())
def act(self, state, noise=0.0):
state = torch.FloatTensor(state).unsqueeze(0).to(self.device)
self.actor_local.eval()
with torch.no_grad():
action = self.actor_local(state).cpu().data.numpy()
self.actor_local.train()
action += noise * np.random.randn(*action.shape)
return np.clip(action, -1, 1)[0]
def step_epsilon_decay(self):
self.epsilon = max(EPSILON_END, self.epsilon - EPSILON_DECAY)
def learn(self, experiences, agents, buffer):
states, actions, rewards, next_states, dones = experiences
# Reshape states and next_states to (batch_size, num_agents, state_size)
states = torch.FloatTensor(states).to(self.device).view(states.shape[0], self.num_agents, self.state_size)
actions = torch.FloatTensor(actions).to(self.device).view(actions.shape[0], self.num_agents, self.action_size)
next_states = torch.FloatTensor(next_states).to(self.device).view(next_states.shape[0], self.num_agents, self.state_size)
rewards = torch.FloatTensor(rewards[:, self.agent_id]).unsqueeze(1).to(self.device)
dones = torch.FloatTensor(dones[:, self.agent_id]).unsqueeze(1).to(self.device)
# Update Critic
# Get actions for next states from target actors
with torch.no_grad():
next_actions = []
for i, agent in enumerate(agents):
next_action = agent.actor_target(next_states[:, i, :])
next_actions.append(next_action)
next_actions = torch.cat(next_actions, dim=1)
next_states_flat = next_states.view(next_states.size(0), -1)
q_targets_next = self.critic_target(next_states_flat, next_actions)
q_targets = rewards + (GAMMA * q_targets_next * (1 - dones))
states_flat = states.view(states.size(0), -1)
actions_flat = actions.view(actions.size(0), -1)
q_expected = self.critic_local(states_flat, actions_flat)
critic_loss = nn.MSELoss()(q_expected, q_targets)
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# Update Actor
# Get actions from local actor
actions_pred = []
for i, agent in enumerate(agents):
action_pred = agent.actor_local(states[:, i, :])
actions_pred.append(action_pred)
actions_pred = torch.cat(actions_pred, dim=1)
actor_loss = -self.critic_local(states_flat, actions_pred).mean()
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
# Soft update target networks
self.soft_update(self.actor_target, self.actor_local)
self.soft_update(self.critic_target, self.critic_local)
def soft_update(self, target, source):
for target_param, param in zip(target.parameters(), source.parameters()):
target_param.data.copy_(TAU * param.data + (1.0 - TAU) * target_param.data)
# Custom Multi-Agent CartPole Environment
class MultiAgentCartPoleEnv(gym.Env):
"""
Custom Multi-Agent CartPole Environment using Gymnasium.
Each agent controls a separate CartPole system.
"""
metadata = {"render_modes": ["human"], "render_fps": 50}
def __init__(self, num_agents=2, render_mode=None):
super(MultiAgentCartPoleEnv, self).__init__()
self.num_agents = num_agents
self.render_mode = render_mode
# Define action and observation space for each agent
# Actions: Apply force left or right (continuous)
self.action_space = spaces.Box(low=-1.0, high=1.0, shape=(self.num_agents, 1), dtype=np.float32)
# Observations: Cart Position, Cart Velocity, Pole Angle, Pole Angular Velocity for each agent
high = np.array([4.8, np.finfo(np.float32).max, np.pi/2, np.finfo(np.float32).max] * self.num_agents, dtype=np.float32)
self.observation_space = spaces.Box(low=-high, high=high, dtype=np.float32)
# Initialize state
self.state = None
# Physics parameters
self.gravity = 9.8
self.masscart = 1.0
self.masspole = 0.1
self.total_mass = self.masscart + self.masspole
self.length = 0.5 # Half-length of the pole
self.polemass_length = self.masspole * self.length
self.force_mag = 10.0
self.tau = 0.02 # Time step
# Episode parameters
self.max_steps = MAX_STEPS
self.current_step = 0
# Rendering parameters
if self.render_mode == "human":
self.screen = None
self.clock = None
self.screen_width = 800
self.screen_height = 600
self.cart_width = 50
self.cart_height = 30
self.pole_length_px = 100 # Length of the pole in pixels
self.cart_color = (0, 0, 0) # Black
self.pole_color = (255, 0, 0) # Red
self.background_color = (255, 255, 255) # White
def seed(self, seed=None):
self.np_random, seed = gym.utils.seeding.np_random(seed)
return [seed]
def reset(self, seed=None, options=None):
super().reset(seed=seed)
# Initialize state with small random values for each agent and ensure dtype is float32
self.state = self.np_random.uniform(low=-0.05, high=0.05, size=(self.num_agents, 4)).astype(np.float32)
self.current_step = 0
return self.state.flatten(), {}
def step(self, action):
action = np.clip(action, -1.0, 1.0) # Ensure actions are within bounds
actions = action * self.force_mag # Scale actions
rewards = np.ones(self.num_agents, dtype=np.float32)
dones = np.zeros(self.num_agents, dtype=bool)
for i in range(self.num_agents):
x, x_dot, theta, theta_dot = self.state[i]
force = actions[i][0]
costheta = np.cos(theta)
sintheta = np.sin(theta)
# Dynamics equations
temp = (force + self.polemass_length * theta_dot ** 2 * sintheta) / self.total_mass
theta_acc = (self.gravity * sintheta - costheta * temp) / \
(self.length * (4.0/3.0 - self.masspole * costheta ** 2 / self.total_mass))
x_acc = temp - self.polemass_length * theta_acc * costheta / self.total_mass
# Update the state using Euler's method
x += self.tau * x_dot
x_dot += self.tau * x_acc
theta += self.tau * theta_dot
theta_dot += self.tau * theta_acc
# Update state and ensure dtype is float32
self.state[i] = np.array([x, x_dot, theta, theta_dot], dtype=np.float32)
# Check termination conditions
done = bool(
x < -2.4
or x > 2.4
or theta < -12 * np.pi / 180
or theta > 12 * np.pi / 180
or self.current_step >= self.max_steps
)
dones[i] = done
rewards[i] = 1.0 if not done else 0.0
self.current_step += 1
done_env = bool(np.any(dones)) or self.current_step >= self.max_steps
dones = dones.tolist()
return self.state.flatten(), rewards.tolist(), done_env, dones, {}
def render(self, mode="human"):
if self.render_mode != "human":
return
if self.screen is None:
pygame.init()
pygame.display.init()
self.screen = pygame.display.set_mode((self.screen_width, self.screen_height))
if self.clock is None:
self.clock = pygame.time.Clock()
self.screen.fill(self.background_color)
for i in range(self.num_agents):
x, _, theta, _ = self.state[i]
# Convert to pixel coordinates
cart_x = int(self.screen_width / (self.num_agents + 1) * (i + 1))
cart_y = self.screen_height // 2
pole_end_x = cart_x + int(self.pole_length_px * np.sin(theta))
pole_end_y = cart_y - int(self.pole_length_px * np.cos(theta))
# Draw cart
cart_rect = pygame.Rect(0, 0, self.cart_width, self.cart_height)
cart_rect.center = (cart_x, cart_y)
pygame.draw.rect(self.screen, self.cart_color, cart_rect)
# Draw pole
pygame.draw.line(self.screen, self.pole_color, (cart_x, cart_y),
(pole_end_x, pole_end_y), 5)
pygame.display.flip()
self.clock.tick(self.metadata["render_fps"])
def close(self):
if self.render_mode == "human":
if self.screen is not None:
pygame.display.quit()
pygame.quit()
self.screen = None
self.clock = None
# Main Training Loop
def main():
num_agents = 2
env = MultiAgentCartPoleEnv(num_agents=num_agents, render_mode=None)
env.seed(SEED)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Initialize agents
agents = [MADDPGAgent(state_size=4, action_size=1, num_agents=num_agents, agent_id=i, device=device) for i in range(num_agents)]
# Initialize Replay Buffer
buffer = ReplayBuffer(BUFFER_SIZE, BATCH_SIZE, num_agents)
episode_rewards = [0.0 for _ in range(num_agents)]
average_rewards = [0.0 for _ in range(num_agents)]
all_rewards = [[] for _ in range(num_agents)]
for episode in range(1, NUM_EPISODES + 1):
state, _ = env.reset()
done = False
episode_reward = [0.0 for _ in range(num_agents)]
step = 0
while not done and step < MAX_STEPS:
actions = []
for i, agent in enumerate(agents):
agent_action = agent.act(state[i*4:(i+1)*4], noise=agents[i].epsilon)
actions.append(agent_action)
actions = np.array(actions).reshape(-1, 1).astype(np.float32)
next_state, rewards, done_env, dones, _ = env.step(actions)
buffer.add(state, actions, rewards, next_state, dones)
state = next_state
for i in range(num_agents):
episode_reward[i] += rewards[i]
# Learn every UPDATE_EVERY steps
if len(buffer) > BATCH_SIZE and step % UPDATE_EVERY == 0:
experiences = buffer.sample()
for i, agent in enumerate(agents):
agent.learn(experiences, agents, buffer)
step += 1
for i in range(num_agents):
episode_rewards[i] += episode_reward[i]
all_rewards[i].append(episode_reward[i])
average_rewards[i] = np.mean(all_rewards[i][-100:])
# Decay epsilon
for agent in agents:
agent.step_epsilon_decay()
print(f"Episode {episode}/{NUM_EPISODES} | Rewards: {episode_reward} | Avg Rewards: {average_rewards}")
# Plotting the results
for i in range(num_agents):
plt.plot(all_rewards[i], label=f'Agent {i+1}')
plt.xlabel('Episode')
plt.ylabel('Reward')
plt.title('MADDPG Training Rewards')
plt.legend()
plt.show()
# Evaluation
print("Starting Evaluation...")
env.render_mode = "human"
env = MultiAgentCartPoleEnv(num_agents=num_agents, render_mode="human")
env.seed(SEED)
for agent in agents:
agent.actor_local.eval()
for episode in range(3):
state, _ = env.reset()
done = False
episode_reward = [0.0 for _ in range(num_agents)]
step = 0
while not done and step < MAX_STEPS:
actions = []
for i, agent in enumerate(agents):
agent_action = agent.act(state[i*4:(i+1)*4], noise=0.0) # No noise during evaluation
actions.append(agent_action)
actions = np.array(actions).reshape(-1, 1).astype(np.float32)
next_state, rewards, done_env, dones, _ = env.step(actions)
state = next_state
for i in range(num_agents):
episode_reward[i] += rewards[i]
env.render()
time.sleep(env.tau) # Sync with the simulation time step
step += 1
print(f"Evaluation Episode {episode+1}: Rewards: {episode_reward}")
env.close()
print("Evaluation Completed.")
if __name__ == "__main__":
main()
The provided Python code defines neural network architectures for both the Actor and Critic models, tailored to handle the state and action spaces of multiple agents. A ReplayBuffer class is utilized to store and sample experiences, facilitating stable and efficient learning. Each MADDPGAgent maintains its own Actor and Critic networks, alongside target networks for smooth updates, and interacts with the environment by selecting actions, receiving rewards, and updating its policies based on sampled experiences. The main training loop runs for a specified number of episodes, where agents continuously interact with the environment, collect experiences, and periodically update their networks using the MADDPG algorithm. Additionally, the script includes an evaluation phase where the trained agents perform without exploration noise, rendering the environment visually using Pygame to demonstrate their learned behaviors. Throughout training, rewards are tracked and plotted to monitor performance, showcasing the agents' ability to collaboratively balance their respective poles. This architecture leverages the strengths of Gymnasium for environment simulation and PyTorch for flexible and efficient neural network training, enabling the development of sophisticated multi-agent reinforcement learning systems.
Leveraging Gymnasium and PyTorch significantly enhances the implementation of the MADDPG algorithm by providing a robust and flexible foundation for environment interaction and neural network training. Gymnasium's standardized API simplifies the creation and management of multi-agent environments, ensuring compatibility and ease of experimentation across different scenarios. Its support for complex action and observation spaces accommodates the intricate interactions inherent in multi-agent systems. PyTorch's dynamic computation graph and extensive library of neural network components streamline the development of the actor and critic networks essential for MADDPG. Furthermore, PyTorch's efficient tensor operations and automatic differentiation capabilities facilitate rapid experimentation and optimization, enabling agents to learn effectively from high-dimensional observations and continuous action spaces. Together, Gymnasium and PyTorch create a powerful ecosystem that supports the development, training, and evaluation of sophisticated multi-agent reinforcement learning algorithms like MADDPG.
20.5. Case Study: Building a Hybrid Rust-Python Environment
In modern robotics and autonomous systems, deploying machine learning models in production environments demands a balance between rapid development and high-performance execution. While frameworks like Gymnasium and PyTorch offer unparalleled ease for developing and training reinforcement learning algorithms such as MADDPG, real-world applications often require the efficiency, safety, and concurrency capabilities that languages like Rust provide. Imagine a scenario where a reinforcement learning model trained in Python needs to be integrated into a high-performance robotic control system written in Rust. Here, Rust can handle the real-time, low-latency operations essential for controlling hardware, while Python manages the complex decision-making and learning processes. To bridge these two components, Inter-Process Communication (IPC) mechanisms enable seamless and efficient data exchange between the Python-based MADDPG model and the Rust-based control system, ensuring that the combined system operates both intelligently and reliably in demanding deployment environments.
The implementation involves creating a Rust program that establishes a TCP client to communicate with the Python MADDPG server. The Python program, acting as the server, continuously sends sensor data or environment states to the Rust client. Upon receiving this data, the Rust program forwards it to the MADDPG model for processing. The Python server then computes the appropriate actions based on the MADDPG policy and sends these actions back to the Rust client. The Rust program receives the actions and executes them within the robotic control system. This bidirectional communication is facilitated using structured messages, typically serialized in formats like JSON or Protocol Buffers, ensuring that data is accurately interpreted on both ends. The Rust program leverages asynchronous I/O operations to handle communication without blocking critical control processes, maintaining the system's responsiveness and efficiency.
This architecture offers several significant benefits. By leveraging Rust for deployment, the system gains enhanced performance, memory safety, and concurrency, which are crucial for real-time robotic applications. Rust's strong type system and ownership model prevent common bugs and ensure that the control system operates reliably under various conditions. Meanwhile, Python's rich ecosystem and ease of use accelerate the development and training of complex reinforcement learning models like MADDPG. The IPC mechanism ensures that both components can be developed and optimized independently, allowing teams to utilize the best tools for each aspect of the system. Furthermore, this separation of concerns enhances scalability and maintainability, as updates or improvements to the learning model or control logic can be made without disrupting the other component. Overall, integrating Rust and Python through IPC marries the rapid development capabilities of Python with the robust performance of Rust, creating a powerful and flexible system suitable for sophisticated autonomous applications.
Below is a Rust program that communicates with the MADDPG Python program using TCP sockets for Inter-Process Communication (IPC). This Rust client sends environment states to the Python server and receives action commands in response. The communication uses JSON for structured data exchange, ensuring compatibility and ease of parsing on both ends.
[dependencies]
tokio = { version = "1", features = ["full"] }
serde = { version = "1.0", features = ["derive"] }
serde_json = "1.0"
use serde::{Deserialize, Serialize};
use serde_json::Result as SerdeResult;
use std::error::Error;
use tokio::io::{AsyncBufReadExt, AsyncWriteExt, BufReader};
use tokio::net::{TcpStream};
use tokio::net::tcp::OwnedWriteHalf;
// Define the structure for the environment state sent to Python
#[derive(Serialize, Deserialize, Debug)]
struct EnvState {
agent_id: usize,
position: f32,
velocity: f32,
angle: f32,
angular_velocity: f32,
}
// Define the structure for the action received from Python
#[derive(Serialize, Deserialize, Debug)]
struct Action {
agent_id: usize,
force: f32,
}
#[tokio::main] // The tokio::main macro allows async main
async fn main() -> Result<(), Box<dyn Error>> {
// Define the server address and port (ensure it matches the Python server)
let server_addr = "127.0.0.1:8080";
// Connect to the Python MADDPG server
let stream = TcpStream::connect(server_addr).await?;
println!("Connected to server at {}", server_addr);
let (reader, mut writer) = stream.into_split();
let mut reader = BufReader::new(reader);
let mut lines = reader.lines();
// Example: Initial state for each agent
// In a real scenario, this data would come from sensors or the environment
let initial_states = vec![
EnvState {
agent_id: 1,
position: 0.0,
velocity: 0.0,
angle: 0.05,
angular_velocity: 0.0,
},
EnvState {
agent_id: 2,
position: 0.0,
velocity: 0.0,
angle: -0.05,
angular_velocity: 0.0,
},
];
// Send initial states to the Python server
for state in &initial_states {
send_state(&mut writer, state).await?;
}
// Main loop: Continuously send updated states and receive actions
loop {
// Simulate environment state updates
let updated_states = update_states(&initial_states);
// Send updated states to the Python server
for state in &updated_states {
send_state(&mut writer, state).await?;
}
// Listen for actions from the Python server
while let Some(line) = lines.next_line().await? {
let action: Action = match serde_json::from_str(&line) {
Ok(act) => act,
Err(e) => {
eprintln!("Failed to deserialize action: {}", e);
continue;
}
};
println!("Received action: {:?}", action);
// Execute the action within the Rust-based control system
execute_action(action).await;
}
// If we reach here, the server closed the connection
break;
}
Ok(())
}
// Function to send an EnvState to the Python server
async fn send_state(writer: &mut OwnedWriteHalf, state: &EnvState) -> Result<(), Box<dyn Error>> {
let serialized = serde_json::to_string(state)?; // returns serde_json::Error on failure
writer.write_all(serialized.as_bytes()).await?; // returns std::io::Error on failure
writer.write_all(b"\n").await?; // also returns std::io::Error on failure
println!("Sent state: {:?}", state);
Ok(())
}
// Function to simulate environment state updates
fn update_states(initial_states: &Vec<EnvState>) -> Vec<EnvState> {
let mut updated_states = Vec::new();
for state in initial_states {
// Simple simulation: Slightly adjust position and angle
let new_position = state.position + state.velocity * 0.02;
let new_velocity = state.velocity; // No acceleration in this example
let new_angle = state.angle + state.angular_velocity * 0.02;
let new_angular_velocity = state.angular_velocity; // No angular acceleration
updated_states.push(EnvState {
agent_id: state.agent_id,
position: new_position,
velocity: new_velocity,
angle: new_angle,
angular_velocity: new_angular_velocity,
});
}
updated_states
}
// Function to execute the received action
async fn execute_action(action: Action) {
// Placeholder for executing the action
// Integrate with the Rust control system here
println!(
"Executing action for Agent {}: Applying force {:.2}",
action.agent_id, action.force
);
// Example: Update internal state or send commands to hardware
// ...
}
The Rust program effectively bridges high-performance real-time control systems with sophisticated machine learning models developed in Python by utilizing key dependencies and structured data handling. It employs Tokio, an asynchronous runtime that enables non-blocking I/O operations essential for maintaining responsive communication, and Serde along with Serde_JSON for seamless serialization and deserialization of data structures into JSON format. The core data structures include EnvState, which encapsulates an agent's current state with attributes like position, velocity, angle, and angular velocity, and Action, which specifies the force an agent should apply based on the MADDPG policy. In the main function, the program establishes a TCP connection to a Python MADDPG server running on 127.0.0.1:8080, then splits the TCP stream into separate reader and writer components to handle incoming and outgoing data concurrently. It initiates communication by sending the initial states of each agent in JSON format to the Python server. The program then enters a continuous loop where it listens for incoming action commands from the server, deserializes these actions, and invokes the execute_action function. This function acts as a placeholder for integrating the received actions into the Rust-based control logic, where, in a real deployment, it would interface with hardware components or other system elements to apply the specified forces. This architecture ensures efficient, real-time execution of control commands derived from advanced machine learning models, leveraging Rust's performance and safety alongside Python's development ease.
To facilitate testing and demonstrate the interaction between the Rust client and the Python MADDPG server, here's a simple Python server script. This server listens for environment states from the Rust client, processes them using a dummy MADDPG policy (replace with your actual policy), and sends back actions.
import asyncio
import json
# Example MADDPG policy function (replace with actual MADDPG implementation)
def compute_action(env_state):
# Placeholder: Apply a simple rule or integrate with MADDPG
# For demonstration, apply a force proportional to the angle
Kp = 10.0 # Proportional gain
force = -Kp * env_state['angle']
# Clamp the force to the allowable range
force = max(-10.0, min(10.0, force))
return {
'agent_id': env_state['agent_id'],
'force': force
}
async def handle_client(reader, writer):
addr = writer.get_extra_info('peername')
print(f"Connected with {addr}")
while True:
try:
data = await reader.readline()
if not data:
print(f"Connection closed by {addr}")
break
message = data.decode().strip()
if not message:
continue
env_state = json.loads(message)
print(f"Received state: {env_state}")
# Compute action using the MADDPG policy
action = compute_action(env_state)
response = json.dumps(action) + '\n'
writer.write(response.encode())
await writer.drain()
print(f"Sent action: {action}")
except json.JSONDecodeError as e:
print(f"JSON decode error: {e}")
continue
except Exception as e:
print(f"Error: {e}")
break
writer.close()
await writer.wait_closed()
print(f"Disconnected from {addr}")
async def main():
server = await asyncio.start_server(handle_client, '127.0.0.1', 8080)
addr = server.sockets[0].getsockname()
print(f'Serving on {addr}')
async with server:
await server.serve_forever()
if __name__ == "__main__":
asyncio.run(main())
Note: Replace the compute_action function with your actual MADDPG policy inference logic to generate appropriate actions based on the received environment states.
The Python server complements the Rust client by handling incoming environment states, processing them using a reinforcement learning policy, and sending back appropriate actions. It relies on Asyncio for managing asynchronous networking operations, enabling the server to handle multiple client connections efficiently without blocking. The JSON library is employed for serializing and deserializing data structures, ensuring that the data exchanged between Python and Rust adheres to a consistent and interpretable format. The server defines a compute_action function, which currently implements a dummy MADDPG policy that applies a proportional control based on the pole's angle; this function is intended to be replaced with the actual MADDPG model's inference logic for generating sophisticated actions. The handle_client asynchronous function manages each client connection by continuously reading incoming environment states, deserializing the JSON data into the EnvState structure, computing the corresponding Action using the policy function, serializing the action back into JSON, and sending it to the client. The main function sets up the server to bind to 127.0.0.1:8080, starts listening for incoming connections, and maintains the server in an indefinite serving state to handle multiple clients concurrently. This architecture ensures that the Python server can efficiently process real-time data from Rust clients, apply complex reinforcement learning policies, and respond with precise control actions, thereby enabling the deployment of intelligent and responsive autonomous systems.
This architecture leverages the strengths of both Rust and Python to create a robust and efficient deployment pipeline for reinforcement learning models. Python, with its rich ecosystem and ease of use, facilitates rapid development, experimentation, and training of complex models like MADDPG using Gymnasium and PyTorch. Once trained, the model can be integrated into a high-performance Rust-based control system through IPC mechanisms such as TCP sockets. Rust offers superior performance, memory safety, and concurrency capabilities, making it ideal for real-time applications where latency and reliability are critical. By decoupling the learning and control components, developers can optimize each part independently, ensuring that the control system remains responsive and stable while the Python component handles the computationally intensive decision-making processes. Additionally, this separation enhances maintainability and scalability, allowing teams to update or replace components without affecting the other. The use of structured data formats like JSON ensures clear and consistent communication, reducing the likelihood of integration errors. Overall, this Rust-Python IPC architecture provides a seamless bridge between advanced machine learning models and high-performance deployment environments, enabling the creation of intelligent systems that are both powerful and reliable.
This Rust-Python IPC setup enables developers to utilize Python's powerful machine learning frameworks for training sophisticated agents while deploying Rust's high-performance capabilities for real-time control systems. By maintaining a clear communication protocol and ensuring data consistency (e.g., using float32), this architecture ensures reliable and efficient operation suitable for demanding deployment scenarios such as robotics, autonomous vehicles, and industrial automation. Further enhancements can include implementing more sophisticated serialization methods (like Protocol Buffers), adding error handling and reconnection logic, and integrating actual control mechanisms within the Rust client to interact with hardware components. Feel free to customize the environment update logic, MADDPG policy, and action execution to fit your specific application needs.
In modern DRL applications, it is common to combine the strengths of multiple languages to achieve both development efficiency and computational performance. Python, with its rich ecosystem and ease of prototyping, is frequently used for high-level tasks such as designing interfaces, integrating with machine learning frameworks, and managing experiments. Rust, on the other hand, offers robust performance, strict memory safety guarantees, and low-level control over computations. By integrating Python and Rust, developers can create hybrid architectures that are both user-friendly and performant. This example presents a 2D robotic arm environment where the goal is to control the arm’s joints so that its end-effector reaches a specified target position. The environment’s state space consists of joint angles and velocities, and the action space comprises torques applied to each joint. The environment follows Markov Decision Process conventions, with the transition function governed by the physics of the system. The reward function encourages proximity to the target while discouraging unnecessarily large torques. Python serves as the front-end, providing an interface compatible with the Gymnasium API, supporting visualization with Pygame, and integrating easily with reinforcement learning libraries such as stable-baselines3 or RLlib. Rust handles the back-end calculations, implementing the environment’s step and reset logic, computing state transitions, and calculating rewards. This code uses PyO3 to bridge Python and Rust, enabling efficient and transparent communication. The resulting setup allows for modularity, maintainability, and the ability to scale to more complex scenarios. The following code snippets illustrate a working hybrid environment, along with a demonstration of random actions being taken and the environment rendered in real time.
Lets develop a hybrid simulation environment combining Python’s flexibility and ecosystem richness with Rust’s efficiency and memory safety. This approach demonstrates how to harness the best features of both languages, showcasing a real-world example of seamless integration. By leveraging Python for user-friendly interfaces and rapid prototyping while relying on Rust for performance-critical components, we create a hybrid architecture that exemplifies modern reinforcement learning practices.
The hybrid environment simulates a robotic arm navigating a 2D space to reach a target position. The environment's state includes the arm’s joint angles and velocities, and the agent receives observations and rewards based on its actions. Python is used for high-level environment interaction and integration with machine learning libraries, while Rust handles the physics calculations and environment dynamics.
The environment operates within the Markov Decision Process (MDP) framework. Let the state space $S$ represent the joint angles and velocities of the robotic arm, and the action space $A$ describe the torques applied to each joint. The transition function $P(s'|s, a)$ is defined by the physical dynamics, modeled in Rust. The reward function$R(s, a)$ incentivizes the agent to minimize the distance to the target while penalizing excessive torque usage.
The architecture separates responsibilities between Python and Rust, maximizing the strengths of each. Python serves as the front-end for interacting with the environment, visualizing results, and integrating RL algorithms. Rust handles the back-end, performing computationally intensive operations like state updates and physics simulation. Communication between Python and Rust is facilitated through Foreign Function Interface (FFI) bindings using the PyO3 library. This modular design ensures scalability, maintainability, and performance.
Create a directory named hybrid_env and place the following files inside it. Make sure you have Rust and Cargo installed, and also maturin for building Python packages from Rust. The Rust code defines a RoboticArmEnv class, implementing environment initialization, reset, and step logic. States are represented by joint angles and velocities, while actions are torques applied to each joint. The state transitions follow basic physics computations, and a simple distance-based reward function encourages reaching the target.
[package]
name = "hybrid_env"
version = "0.1.0"
edition = "2021"
[lib]
name = "hybrid_env"
crate-type = ["cdylib"]
[dependencies]
pyo3 = { version = "0.18", features = ["extension-module"] }
rand = "0.8"
use pyo3::prelude::*;
use rand::Rng;
use std::f32::consts::PI;
const NUM_JOINTS: usize = 2;
const MAX_ANGLE: f32 = PI;
const MAX_VELOCITY: f32 = 5.0;
const DT: f32 = 0.02;
const TARGET_X: f32 = 1.0;
const TARGET_Y: f32 = 1.0;
const ARM_LENGTHS: [f32; NUM_JOINTS] = [1.0, 0.7];
#[pyclass]
struct RoboticArmEnv {
angles: [f32; NUM_JOINTS],
velocities: [f32; NUM_JOINTS],
step_count: usize,
max_steps: usize,
}
#[pymethods]
impl RoboticArmEnv {
#[new]
fn new(max_steps: usize) -> Self {
let mut rng = rand::thread_rng();
let angles = [rng.gen_range(-0.05..0.05), rng.gen_range(-0.05..0.05)];
let velocities = [0.0; NUM_JOINTS];
RoboticArmEnv {
angles,
velocities,
step_count: 0,
max_steps,
}
}
fn reset(&mut self) -> Vec<f32> {
let mut rng = rand::thread_rng();
self.angles = [rng.gen_range(-0.05..0.05), rng.gen_range(-0.05..0.05)];
self.velocities = [0.0; NUM_JOINTS];
self.step_count = 0;
self.get_state()
}
fn step(&mut self, actions: Vec<f32>) -> (Vec<f32>, f32, bool) {
assert_eq!(actions.len(), NUM_JOINTS);
for i in 0..NUM_JOINTS {
let torque = actions[i];
let angle_acc = torque;
self.velocities[i] += angle_acc * DT;
if self.velocities[i] > MAX_VELOCITY {
self.velocities[i] = MAX_VELOCITY;
} else if self.velocities[i] < -MAX_VELOCITY {
self.velocities[i] = -MAX_VELOCITY;
}
self.angles[i] += self.velocities[i] * DT;
if self.angles[i] > MAX_ANGLE {
self.angles[i] -= 2.0 * MAX_ANGLE;
} else if self.angles[i] < -MAX_ANGLE {
self.angles[i] += 2.0 * MAX_ANGLE;
}
}
self.step_count += 1;
let state = self.get_state();
let (done, reward) = self.compute_reward_done();
(state, reward, done)
}
fn observation_size(&self) -> usize {
NUM_JOINTS * 2
}
fn action_size(&self) -> usize {
NUM_JOINTS
}
fn get_state(&self) -> Vec<f32> {
let mut state = Vec::with_capacity(NUM_JOINTS*2);
state.extend_from_slice(&self.angles);
state.extend_from_slice(&self.velocities);
state
}
}
impl RoboticArmEnv {
fn compute_end_effector_position(&self) -> (f32, f32) {
let x1 = ARM_LENGTHS[0] * self.angles[0].cos();
let y1 = ARM_LENGTHS[0] * self.angles[0].sin();
let x2 = x1 + ARM_LENGTHS[1] * (self.angles[0] + self.angles[1]).cos();
let y2 = y1 + ARM_LENGTHS[1] * (self.angles[0] + self.angles[1]).sin();
(x2, y2)
}
fn compute_reward_done(&self) -> (bool, f32) {
let (x, y) = self.compute_end_effector_position();
let dist = ((x - TARGET_X).powi(2) + (y - TARGET_Y).powi(2)).sqrt();
let reward = -dist;
let done = dist < 0.05 || self.step_count >= self.max_steps;
(done, reward)
}
}
#[pymodule]
fn hybrid_env(_py: Python, m: &PyModule) -> PyResult<()> {
m.add_class::<RoboticArmEnv>()?;
Ok(())
}
Build the Rust library:
cd hybrid_env
maturin build --release
pip install target/wheels/hybrid_env-0.1.0-*.whl
The Python code defines a RustRoboticArmEnv class that follows the Gymnasium API, making it easy to integrate with reinforcement learning frameworks. It communicates with the Rust environment using the PyO3 bindings, calling methods like reset() and step() on the Rust object. The Python code also handles visualization using Pygame, drawing the arm and target on a 2D canvas. After running the environment with random actions, the script prints the total reward and closes the environment.
import gymnasium as gym
from gymnasium import spaces
import numpy as np
import pygame
import time
import matplotlib.pyplot as plt
import hybrid_env
class RustRoboticArmEnv(gym.Env):
metadata = {"render_modes": ["human"], "render_fps": 50}
def __init__(self, render_mode=None, max_steps=200):
super().__init__()
self.render_mode = render_mode
self.env = hybrid_env.RoboticArmEnv(max_steps)
obs_size = self.env.observation_size()
act_size = self.env.action_size()
self.action_space = spaces.Box(low=-1.0, high=1.0, shape=(act_size,), dtype=np.float32)
high = np.array([np.pi, np.pi, 5.0, 5.0], dtype=np.float32)
self.observation_space = spaces.Box(low=-high, high=high, dtype=np.float32)
self.screen = None
self.clock = None
self.screen_width = 600
self.screen_height = 600
self.arm_lengths = [1.0, 0.7]
self.target_pos = np.array([1.0, 1.0])
def reset(self, seed=None, options=None):
super().reset(seed=seed)
obs = self.env.reset()
return np.array(obs, dtype=np.float32), {}
def step(self, action):
obs, reward, done = self.env.step(action.tolist())
info = {}
return np.array(obs, dtype=np.float32), reward, done, False, info
def render(self):
if self.render_mode != "human":
return
if self.screen is None:
pygame.init()
pygame.display.init()
self.screen = pygame.display.set_mode((self.screen_width, self.screen_height))
self.clock = pygame.time.Clock()
self.screen.fill((255, 255, 255))
obs = self.env.get_state()
angles = obs[:2]
x1 = self.arm_lengths[0] * np.cos(angles[0])
y1 = self.arm_lengths[0] * np.sin(angles[0])
x2 = x1 + self.arm_lengths[1] * np.cos(angles[0] + angles[1])
y2 = y1 + self.arm_lengths[1] * np.sin(angles[0] + angles[1])
center_x = self.screen_width // 2
center_y = self.screen_height // 2
scale = 100.0
start = (center_x, center_y)
joint = (int(center_x + x1 * scale), int(center_y - y1 * scale))
end = (int(center_x + x2 * scale), int(center_y - y2 * scale))
pygame.draw.line(self.screen, (0, 0, 0), start, joint, 5)
pygame.draw.line(self.screen, (0, 0, 0), joint, end, 5)
tx = int(center_x + self.target_pos[0] * scale)
ty = int(center_y - self.target_pos[1] * scale)
pygame.draw.circle(self.screen, (255, 0, 0), (tx, ty), 5)
pygame.display.flip()
self.clock.tick(self.metadata["render_fps"])
def close(self):
if self.screen:
pygame.display.quit()
pygame.quit()
self.screen = None
self.clock = None
if __name__ == "__main__":
env = RustRoboticArmEnv(render_mode="human", max_steps=200)
obs, _ = env.reset()
done = False
total_reward = 0.0
for _ in range(200):
action = env.action_space.sample()
obs, reward, done, truncated, info = env.step(action)
total_reward += reward
env.render()
time.sleep(0.01)
if done:
break
print("Episode ended with total reward:", total_reward)
env.close()
The Python code defines a RustRoboticArmEnv class that follows the Gymnasium API, making it easy to integrate with reinforcement learning frameworks. It communicates with the Rust environment using the PyO3 bindings, calling methods like reset() and step() on the Rust object. The Python code also handles visualization using Pygame, drawing the arm and target on a 2D canvas. After running the environment with random actions, the script prints the total reward and closes the environment.
This architecture ensures that performance-critical operations run in Rust, while Python offers flexibility in experimenting with different RL algorithms and visualization. The use of PyO3 and a state-of-the-art approach to environment design creates a modern, extensible, and reliable reinforcement learning setup.
In summary, building hybrid environments combining Python and Rust demonstrates the power of leveraging the best features of both languages. By following a structured approach to design, integration, and testing, we achieve high-performance RL environments that are flexible and scalable. Looking ahead, distributed simulations and multi-agent learning will shape the future of RL frameworks. Developers and researchers are encouraged to contribute to open-source projects, advancing the field through collaborative innovation.
20.11. Conclusion
In conclusion, this chapter has provided an extensive and integrated examination of simulation environments within the realm of reinforcement learning, effectively bridging theoretical concepts with practical applications using both Python and Rust. By elucidating the mathematical structures that underpin RL environments and dissecting the architectural nuances of leading frameworks like OpenAI Gym and Gymnasium, the chapter has established a solid foundation for understanding and developing robust simulation tools. The innovative approach to combining Python’s flexibility with Rust’s performance through various integration methods offers a pragmatic solution to current tooling limitations, empowering developers to harness the strengths of both languages. The hands-on implementations and detailed case study not only illustrate the practical steps required to build and optimize hybrid environments but also highlight the tangible benefits of such integrations in real-world RL tasks. As the field of reinforcement learning continues to evolve, the advanced topics and future directions discussed ensure that readers are prepared to contribute to and innovate within this dynamic landscape.
20.11.1. Further Learning with GenAI
These prompts are designed to elicit the most advanced and in-depth technical insights from GenAI, guiding readers through a comprehensive exploration of simulation environment in reinforcement learning. The questions span foundational theories, complex implementation challenges, nuanced performance optimization techniques, and innovative applications in various domains.
Provide an in-depth mathematical exposition of Markov Decision Processes (MDPs) as the foundational framework for reinforcement learning environments. Include the formal definitions of states, actions, transition probabilities, reward functions, and discount factors. Additionally, illustrate how the Markov property ensures the memorylessness of the process, and present a comprehensive example that demonstrates the formulation of an MDP for a specific RL problem, detailing state transitions, reward structures, and the process of policy optimization.
Conduct a thorough comparative analysis of continuous versus discrete state and action spaces within reinforcement learning environments. Discuss the mathematical challenges inherent to each type of space, such as handling infinite possibilities in continuous spaces and scalability issues in discrete spaces. Explore the various solution approaches, including function approximation techniques for continuous spaces and state aggregation methods for discrete spaces. Provide concrete examples of RL environments that effectively utilize each type of space, highlighting the implications for algorithm selection and performance.
Elaborate on the Bellman equations in the context of value functions and policy evaluation in reinforcement learning. Detail the derivation of both the Bellman Expectation Equation and the Bellman Optimality Equation, and explain their roles in evaluating and improving policies. Discuss the mathematical conditions required for the convergence of these equations, such as the contraction mapping principle. Additionally, explore advanced topics like Temporal Difference (TD) learning and how it leverages the Bellman equations for efficient policy optimization.
Trace the architectural evolution of prominent simulation frameworks like OpenAI Gym and Farama Gymnasium. Analyze how these frameworks have adapted to accommodate the increasing complexity and diversity of reinforcement learning tasks over time. Highlight key architectural changes, such as the introduction of modular environment components, enhanced API designs, and scalability improvements. Discuss the impact of these changes on the usability, extensibility, and performance of the frameworks, and predict future architectural trends based on current developments.
Perform a comprehensive comparative analysis of OpenAI Gym and Gymnasium frameworks, focusing on aspects such as API design, extensibility, community support, performance metrics, and compatibility with various RL algorithms. Evaluate the strengths and weaknesses of each framework in the context of large-scale reinforcement learning projects, considering factors like ease of environment customization, integration capabilities with other tools and libraries, and support for distributed computing. Provide recommendations on framework selection based on specific project requirements and constraints.
Investigate the role and implementation of environment wrappers in OpenAI Gym and Gymnasium. Explain how wrappers can modify, extend, or enhance the functionalities of base environments without altering their core logic. Provide detailed examples of advanced use cases where wrappers are employed to incorporate features such as reward shaping, state normalization, action filtering, and observation augmentation. Discuss best practices for designing and chaining multiple wrappers to achieve complex environment modifications while maintaining code modularity and readability.
Analyze the design principles behind the standardized environment interfaces in Gym and Gymnasium. Explore how these abstractions facilitate interoperability and modularity, enabling seamless integration with various RL algorithms and tools. Discuss the importance of adhering to interface contracts and the implications for environment scalability and maintainability. Provide guidelines and best practices for designing extensible RL environments, including strategies for encapsulating environment logic, managing dependencies, and ensuring compatibility with different versions of the frameworks.
Develop a detailed guide on optimizing the performance of custom reinforcement learning environments implemented in Python using OpenAI Gym. Cover advanced optimization techniques such as vectorization of state and action computations, efficient representation and storage of state information, minimizing computational overhead in environment step functions, and leveraging parallelism through multi-processing or asynchronous execution. Include code examples and benchmark comparisons to illustrate the impact of these optimizations on environment performance and agent training efficiency.
Explain the integration process of advanced reinforcement learning algorithms, such as Proximal Policy Optimization (PPO) or Deep Q-Networks (DQN), with custom environments built in Python. Provide comprehensive code snippets that demonstrate the setup of the environment-agent interaction loop, the implementation of algorithm-specific components (e.g., policy networks, replay buffers), and the handling of environment-specific nuances. Discuss potential integration challenges, such as managing state-action space mismatches, ensuring stable learning dynamics, and optimizing hyperparameters, and propose solutions to address these issues effectively.
Explore advanced Foreign Function Interface (FFI) techniques for integrating Python and Rust in reinforcement learning environments. Delve into the intricacies of memory safety, data type compatibility, and performance optimization when bridging the two languages. Discuss the use of tools like
PyO3andRust-cpythonfor creating Python bindings for Rust code, and provide detailed examples of exposing Rust functions and data structures to Python. Analyze the trade-offs between different FFI approaches, including ease of use, performance overhead, and maintainability, and recommend best practices for achieving seamless and efficient cross-language integration.Analyze the trade-offs between performance and flexibility when integrating Python and Rust for simulation environments in reinforcement learning. Discuss how developers can leverage Rust’s low-level performance advantages while maintaining the high-level flexibility and extensive ecosystem provided by Python. Explore strategies such as minimizing cross-language calls, optimizing data serialization and deserialization, and strategically offloading compute-intensive tasks to Rust. Provide practical examples and benchmarks that illustrate how to maximize Rust’s performance benefits without sacrificing Python’s ease of use and rapid development capabilities.
Detail the process of implementing high-performance environment components in Rust for reinforcement learning. Discuss Rust’s ownership model, borrowing semantics, and concurrency features, and how they contribute to building robust and efficient simulation environments. Provide a step-by-step guide to designing and coding key environment components in Rust, such as state representations, action handlers, and reward calculators. Include code examples that demonstrate the integration of these components with Python, ensuring safe and efficient data exchange between the two languages. Highlight the advantages of using Rust for performance-critical sections of RL environments.
Explain how Rust’s memory safety guarantees and concurrency primitives can be leveraged to develop reliable and scalable reinforcement learning environments. Provide examples of common concurrency patterns used in Rust RL environments, such as multi-threading with
async/await, message passing with channels, and parallel data processing. Discuss how Rust’s type system and ownership model prevent common concurrency issues like data races and deadlocks, ensuring the stability and reliability of simulation environments. Illustrate these concepts with comprehensive code samples and real-world application scenarios.Discuss advanced data serialization techniques for efficient communication between Python and Rust in reinforcement learning environments. Compare and contrast serialization formats such as JSON, MessagePack, Protocol Buffers, and Cap’n Proto in terms of their speed, data size, ease of integration, and support for complex data structures. Provide detailed examples of implementing each serialization method in a Python-Rust integrated environment, highlighting the pros and cons of each approach. Recommend best practices for selecting and implementing serialization formats based on specific project requirements, such as real-time performance, cross-language compatibility, and ease of debugging.
Provide a comprehensive guide on implementing robust inter-process communication (IPC) mechanisms, such as sockets, shared memory, or message queues, for integrating Python and Rust in reinforcement learning simulation environments. Detail the setup and configuration of each IPC method, including handling connection establishment, data transmission protocols, synchronization, and error handling. Discuss the advantages and limitations of each approach in the context of RL environments, and present best practices for ensuring data integrity, minimizing latency, and achieving reliable communication between Python and Rust processes. Include practical code examples and performance benchmarks to illustrate the implementation of each IPC mechanism.
Outline the architectural design of a hybrid reinforcement learning environment that combines Python and Rust, emphasizing component separation, communication protocols, and strategies to ensure seamless interoperability and optimal performance. Discuss how to partition environment functionalities between Python and Rust based on their strengths, such as delegating compute-intensive tasks to Rust while handling high-level logic and agent interactions in Python. Provide a detailed architectural diagram and walk through the interaction flow between components, highlighting the role of each language in the overall system. Include considerations for maintainability, scalability, and extensibility in the architectural design.
Describe methodologies for performance benchmarking of hybrid Python-Rust reinforcement learning environments. Identify key performance metrics to measure, such as execution speed, memory usage, latency in data exchange, and overall system throughput. Discuss the setup of controlled experiments to evaluate the performance of pure Python, pure Rust, and hybrid implementations of the same environment. Present techniques for accurately profiling and analyzing performance data, including the use of benchmarking tools and statistical analysis methods. Provide examples of interpreting benchmarking results to inform optimization strategies and improve the efficiency of the hybrid environment.
Explore scalability strategies for large-scale reinforcement learning simulation environments. Discuss distributed computing approaches, such as parallelizing environment simulations across multiple CPU cores or machines, and leveraging cloud-based resources for elastic scalability. Analyze load balancing techniques to ensure even distribution of computational tasks and prevent bottlenecks. Examine the use of containerization technologies like Docker and orchestration tools like Kubernetes to manage and scale RL environments efficiently. Provide practical examples and best practices for implementing these scalability strategies in Python-Rust integrated environments.
Provide a roadmap for contributing to open-source reinforcement learning frameworks like Gymnasium or developing stable Rust crates for RL environments. Detail the steps involved in setting up the development environment, understanding the project's contribution guidelines, and navigating the codebase. Discuss best practices for writing clean, maintainable, and well-documented code, including the use of version control, automated testing, and continuous integration. Highlight the importance of community engagement, such as participating in discussions, submitting pull requests, and addressing issues. Additionally, outline the process for publishing and maintaining Rust crates, ensuring compatibility, stability, and ease of use for the broader RL community.
Explain how to integrate reinforcement learning simulation environments with advanced visualization and logging tools to enhance monitoring, debugging, and analysis of agent performance. Discuss the selection and implementation of visualization libraries (e.g., Matplotlib, Seaborn, TensorBoard) and logging frameworks (e.g., MLflow, Weights & Biases) in both Python and Rust components of the environment. Provide detailed examples of setting up real-time dashboards to track key performance indicators, visualize state-action trajectories, and analyze learning dynamics. Explore techniques for capturing and storing detailed logs of agent-environment interactions, and demonstrate how to leverage these logs for post-training analysis and debugging. Highlight the benefits of such integrations in facilitating a deeper understanding of agent behaviors and improving the overall training process.
Each prompt is an opportunity to explore the intricacies of simulation environment, pushing your understanding beyond the theoretical into practical, impactful applications. The skills and insights you gain will not only enhance your technical expertise but also empower you to drive the future of reinforcement learning systems. Embrace the challenge, dive deep, and let your curiosity guide you to mastery.
20.11.2. Hands on Practices
Below are 5 comprehensive hands-on assignments designed to reinforce the concepts covered in this chapter. Each assignment offering clear objectives, detailed tasks, and specific deliverables to ensure practical and in-depth learning experiences.
Exercise 20.1: Implementing a Custom OpenAI Gym Environment in Python
Objective:\ Develop a custom reinforcement learning environment using OpenAI Gym in Python, focusing on defining state and action spaces, implementing environment dynamics, and integrating with an RL agent.
Task:
Environment Design:
Define a unique RL problem scenario (e.g., a simple grid world, a resource management task, or a basic robotic simulation).
Clearly specify the state and action spaces using Gym’s
spacesmodule, ensuring appropriate handling of discrete or continuous variables.Environment Implementation:
Implement the environment by subclassing
gym.Env.Define the
__init__,reset,step, andrendermethods.Incorporate reward structures and termination conditions that align with the designed scenario.
Integration with an RL Agent:
Select a basic RL algorithm (e.g., Q-learning or a simple policy gradient method).
Integrate the custom environment with the chosen RL agent.
Train the agent and observe its learning progress within the environment.
Testing and Validation:
Develop unit tests to verify the correctness of environment dynamics, state transitions, and reward assignments.
Ensure that the environment adheres to Gym’s API standards.
Deliverable:\ Submit your fully implemented custom Gym environment along with the RL agent integration code. Additionally, provide a report that includes:
A detailed description of the environment design and rationale.
Code snippets highlighting key implementation aspects.
Training results with visualizations (e.g., learning curves).
Analysis of the agent’s performance and potential improvements.
Exercise 20.2: Bridging Python and Rust Using PyO3 for Enhanced Environment Performance
Objective:\ Integrate Rust with Python using the PyO3 library to enhance the performance of computationally intensive components within a reinforcement learning environment.
Task:
Rust Component Development:
Identify a computationally intensive part of your custom Gym environment (e.g., complex state transition logic or reward calculation).
Implement this component in Rust, ensuring efficient memory management and concurrency where applicable.
Python-Rust Integration with PyO3:
Set up a Rust project with PyO3 to create Python bindings for the Rust component.
Expose the Rust functions to Python, ensuring proper handling of data types and memory safety.
Environment Modification:
Modify the original Python-based Gym environment to utilize the Rust-implemented component through the Python bindings.
Performance Benchmarking:
Benchmark the performance of the environment before and after integrating the Rust component.
Measure metrics such as execution time per step, memory usage, and overall training speed of the RL agent.
Testing and Validation:
Ensure that the integrated environment behaves identically to the original environment in terms of state transitions and rewards.
Develop tests to validate the correctness of the Rust-Python integration.
Deliverable:\ Provide the Rust source code, Python bindings created using PyO3, and the modified Gym environment code. Additionally, include a comprehensive report that covers:
The rationale for selecting the component to implement in Rust.
Detailed steps of the Rust-Python integration process.
Performance benchmarking results with comparative analysis.
Discussion on the benefits and any challenges faced during integration.
Exercise 20.3: Creating and Utilizing Environment Wrappers in Gymnasium
Objective:\ Enhance the functionality of a Gymnasium environment by implementing custom environment wrappers that preprocess observations and modify rewards to improve RL agent performance.
Task:
Custom Wrapper Development:
Design a custom wrapper that preprocesses observations (e.g., normalization, feature scaling, or dimensionality reduction).
Develop another wrapper that modifies the reward structure (e.g., reward shaping, clipping, or adding auxiliary rewards).
Wrapper Implementation:
Implement the custom wrappers by subclassing
gym.Wrapperorgym.ObservationWrapper/gym.RewardWrapperas appropriate.Ensure that the wrappers are modular and can be easily chained or applied to different environments.
Environment Enhancement:
Apply the custom wrappers to your existing Gymnasium environment.
Ensure that the environment maintains compliance with Gymnasium’s API after applying the wrappers.
Agent Training and Evaluation:
Train an RL agent using the wrapped environment.
Compare the agent’s performance with and without the wrappers in terms of convergence speed, stability, and overall performance metrics.
Documentation and Best Practices:
Document the design choices and implementation details of each wrapper.
Discuss best practices for designing effective environment wrappers that enhance agent learning without introducing unintended biases.
Deliverable:\ Submit the source code for the custom wrappers and the modified Gymnasium environment. Additionally, provide a report that includes:
Detailed explanations of the preprocessing and reward modification strategies implemented.
Training results comparing agent performance with and without the wrappers, supported by graphs and statistical analysis.
Insights and recommendations on the impact of wrappers on RL training dynamics.
Exercise 20.4: Developing a High-Performance RL Environment Component in Rust
Objective:\ Implement a high-performance component of a reinforcement learning environment in Rust, leveraging Rust’s ownership model and concurrency features to ensure efficiency and reliability.
Task:
Component Selection and Design:
Choose a critical component of your RL environment that can benefit from Rust’s performance capabilities (e.g., a physics simulation, state transition engine, or complex reward calculator).
Design the component architecture, emphasizing efficient data structures and algorithms suitable for Rust.
Rust Implementation:
Develop the selected component in Rust, ensuring adherence to Rust’s safety and concurrency paradigms.
Optimize the code for performance, utilizing Rust’s features such as zero-cost abstractions, ownership, and borrowing to minimize overhead.
Python Integration:
Create Python bindings for the Rust component using PyO3 or another suitable FFI library.
Ensure seamless communication between Python and Rust, handling data serialization and error management effectively.
Environment Integration and Testing:
Integrate the Rust-implemented component into your existing Python-based RL environment.
Conduct thorough testing to validate the correctness and performance improvements introduced by the Rust component.
Performance Analysis:
Benchmark the environment’s performance before and after integrating the Rust component.
Analyze metrics such as execution time, memory consumption, and scalability under increased load or complexity.
Deliverable:\ Provide the Rust source code, Python bindings, and the updated RL environment code. Additionally, include a detailed report that covers:
The rationale behind selecting the specific component for Rust implementation.
Comprehensive steps of the Rust development and integration process.
Performance benchmarking results with comparative analysis highlighting the enhancements achieved.
Reflections on the benefits and challenges encountered during the Rust-Python integration.
Exercise 20.5: Building and Benchmarking a Hybrid Python-Rust RL Environment
Objective:\ Construct a hybrid reinforcement learning environment that leverages both Python and Rust, and perform comprehensive benchmarking to evaluate the performance benefits of the integration.
Task:
Architectural Design:
Design the architecture of a hybrid RL environment, clearly delineating the responsibilities of Python and Rust components.
Define the communication protocols and data exchange mechanisms between Python and Rust.
Component Development:
Implement the Python-based components (e.g., high-level environment logic, agent interactions) and Rust-based components (e.g., performance-critical computations) as per the architectural design.
Integration Implementation:
Integrate the Python and Rust components using appropriate FFI techniques (e.g., PyO3, Rust-cpython).
Ensure efficient data serialization and minimize communication overhead between the two languages.
Benchmarking and Performance Evaluation:
Develop a benchmarking suite to measure key performance metrics such as execution speed per environment step, memory usage, and agent training time.
Compare the hybrid environment’s performance against purely Python and purely Rust implementations of the same environment.
Analysis and Optimization:
Analyze the benchmarking results to identify performance bottlenecks and areas for optimization.
Implement optimizations based on the analysis to further enhance the hybrid environment’s efficiency.
Documentation and Reporting:
Document the design choices, implementation details, and integration strategies used in building the hybrid environment.
Provide insights into the performance improvements achieved and discuss the trade-offs involved in maintaining a hybrid codebase.
Deliverable:\ Submit the complete source code for the hybrid Python-Rust RL environment, including all integration scripts and benchmarking tools. Additionally, provide a comprehensive report that includes:
Detailed architectural diagrams and explanations.
Benchmarking results with comparative charts and statistical analysis.
Discussion on the performance gains, challenges faced during integration, and the effectiveness of optimizations.
Recommendations for future enhancements and potential applications of hybrid RL environments.
By engaging with these hands-on assignments, you will gain practical experience in designing, implementing, and optimizing reinforcement learning environments using both Python and Rust. These exercises will not only reinforce theoretical knowledge but also develop essential skills for building efficient and scalable RL systems.
Comments